xMarkup is a text transformation utility for processing of a set of text files. The transformations performed by utility can be extremely complicated comparing to ordinal search&replace procedures. Actually the utility uses a procedural language, with help of which any algorithms of text transformations can be implemented. However, using of these procedural extensions are needed only for a few cases. For most cases it is enough to define start and stop marks for searched text elements and describe templates of their transformation.
The utility can be successfuly used both for adding, altering or purging of any text elements in the source files. xMarkup was born initaially as amateur software, but now it is used for preparing publications on the site of Russian Virtul Library. Let us show the obvious ways of the utility usage:
Some exotic usage of the utility can be invented, for example to perform calculations or check program code.
xMarkup utility is implemented as console Win32 application and written on the Icon Programming Language. At some time Icon was changed to Unicon, which is more powerful evolution of Icon Programming Language. As Icon is a cross-platform language the utility can be ported to other systems different from MS Windows. In chapter 9 is described how to use the utility on POSIX/UNIX systems.
xMarkup utility is invoked by following command line:
xm -p file [-f list] [-o path] [ключи]
|
Options:
-p file |
Path to processing script file. |
-f list |
List of file paths delimeted by semicolon characters (;), which define the set of processed files. Path with sign defis (-) ahead is skipped from processing. For example:-f*.htm;*.txt;-index.htm;-index.txtInstead of list itself you can specify the file which includes this list: -f @file. |
-o path |
Output path for results (by default NUL:). To output result on console you can specify CON:. |
Keys:
-c |
Define automatic creation of output path if it doesn't exist. |
-r |
Define recursive search of files in subdirectories. |
-s |
Define prelimenary ordering of processing files list. |
-q L |
Define level L of output statistics: 0 - print full statictics (by default); 1 - suppress output of statistics; 2 - print the list of processing filea only; 3 - print total statistics only (elapsed CPU time and count of processed files). |
-debug |
Define interactive debug mode. |
-help |
Print this help screen. |
-version |
Print info about current version of utility. |
If you get the following error while starting the utility:
| C:\> "c:\Program Files\xmwin\bin"\xm.exe |
| error in startup code |
| xm.exe: cannot open interpreter file |
please add path to utility binary file to PATH environment variable:
| C:\> set path="c:\Program Files\xmwin\bin";%path% |
Version 1.0.1, August of 1999
The initial experimental version of utility is realesed. This version was re-developed afterwards many times. The ugly duckling became the really working program only at summer of 2001.
Version 1.6.3, August of 2001
1. The utility became extendable due to invention of procedural macros written on Icon dialect. It means using of ad hoc markup procedures, in which the calls to all Icon-functions are available!
2. Enchanced counters, which number is unlimited! Added special macro-definitions to generate next values of counters and reset their to initial state.
3. Added macro-definitions @bof, @eof to check position within current text file (begin-of-file and end-of-file).
4. Added macro-definitions @bol, @eol to check position within current line (begin-of-line and end-of-line).
5. Added macro-definitions for character sets and system variables (for example, current time).
6. Added macro-definition @eval() to evaluate the expression "on-the-fly".
Version 1.6.8, February of 2002
1. Fixed minor but annoying bugs.
2. Added possibility to define a set of source files in command line as a list (@file).
3. Added function likeword(s) to check if a substring s likes to word.
4. Added internal macro-definitions @subject (currently processed substring within source line) and
@pos (offset position within @subject).
Version 1.6.9, July of 2002
Fixed found bugs.
Version 1.7.0, September of 2004
1. Added function tabto(i) to move to i-th position of current substring @subject.
Call tabto(0) performs move to the end of line and therefore defines move to the next line.
2. Added function like(s1,s2) to check substring s1 by the search mask s2.
Function returns 1 (true) if s1 satisfies to s2, else fails.
3. Added debug mode, which is defined by parameter debug=true in the section [options].
Version 1.7.1, February of 2005
1. Fixed bugs related to processing of special characters (\c) in the strings.
2. Added logical operation to check non-equality of string expressions ( a !== b ).
3. Enchanced debug output.
4. Adeed keys "-h" и "-d" in the command line of utility.
5. Added macro-definition @nfiles, which defines a total number of processed files.
6. Re-developed examples in this guide to make they maximum simple and clear.
Version 1.7.2, March of 2005
1. Fixed bugs related to using of macro-definitions for start/stop marks.
Version 1.7.3, November of 2005
1. Fixed an error while processing of strings, which ends with sequence of back slash characters (\).
Version 1.8.0, September of 2006
1. Added two predefined macro-procedures "initialize" and "finalize", which are automatically executed at the beginning and finishing of processing. These procedures can be defined in section [macros] if needed.
2. Fixed an error while processing of sequence of start marks @bof, @bol. Previously the first line of text may be skipped for such sequence of start marks.
3. Optimized the search of start/stop marks while processing.
Version 2.0, April of 2007
1. xMarkup GUI released.
2. Fixed an error while processing of compound multi-line structure in figure brackets {...}.
3. Added command line option -c to generate output to directory structure the same as for source files.
4. Added command line option -q1 for GUI integration.
5. Added macro-definition @regexp() to define start/stop marks as regular expressions.
6. Enchanced built-in function substr(), which now returns empty value instead of &fail exception when source string doesn't contain defined substring.
7. Fixed an error in description of macro-definitions @subject and @pos.
8. Added previously missed Cyrillic letters "ё" and "Ё" (yo) to macro-definitions @cp866, @cp1251 and @cletters.
Version 2.0.1, July of 2007
1. Fixed an error in value of @subject (previously the last character of line was missed).
2. Fixed an error when file of parameters is being rewritten each time as processing is started (autosave mode) even it was not changed.
Version 2.1.0, October of 2007
1. Added command line option -x to simulate execution to check correctness of processing script.
2. Added directive @include to include content of external text file to body of script.
3. Added macro-definitions @version, @features, @host, @e and @pi.
4. Added built-in function sql_quotes(s) to change single apostroph character (') to double one ('') within string s.
5. Enchanced GUI - added possibility to change font and color settings for work windows.
6. Console version of xMarkup for POSIX/UNIX-like systems released.
Version 2.1.1, April of 2008
1. Added new features:
@include directive in macros window.2. Fixed some minor bugs and oddities. Fixed the situation when output to direcory structure the same as for source files may fail.
3. Excluded situation when output files may overwrite the source files (input and output paths defined the same by user).
Version 2.1.2, May of 2008
1. Added macro-definition @call, with help of which you can "call" a macro-procedure from body of other macro-procedure.
2. Fixed a stupid error of version 2.1.1, when path to read/write file could not be properly defined if it's not implicitly specified.
Version 2.1.3, September of 2008
1. Added new functions:
eof() to skip processing of the source file and go to its end;file_exists(s) to check existance of the file s;get_separator(), which returns character-separator used in the file paths: (/) for Unix and (\) for Windows;sortfiles(L), which sorts the list of file names L by path and name;2. Added comamnd line's switch -s to sort the list of source files before processing.
3. Revoked default output mode; now to create output files you shall explicitly specify output path in option -o.
4. At Sourceforge.net released source package of xmarkup, which may be used to port utility to required UNIX-like system (see chapter 9 for details).
Version 2.1.4, January of 2009
1. Fixed macros @time, which shall return elapsed time of processing.
2. Fixed GUI - in the previous version doesn't work an output mode in which output files shall be named by adding "xm$" prefix to the name of source files.
3. Changed GUI - link to xmarkup download page added on the tab "Help".
Version 2.1.5, April of 2010
1. Added new functions:
read_input(i) to read a set of lines of current source file;tabto(i) to read characters of current source line;asort(L) to sort list of strings in alphabetical order;unicode(i) to convert decimal Unicode NCR for Cyrillic to Windows-1251 characater;diacritic(i) to convert decimal code of ISO-8859-1 character (diacritics) to named HTML-entity;greek(i) to convert decimal Unicode NCR for Greek to named HTML-entity;utf2ncr(s) to convert UTF-8 string to string of Unicode NCR (&#DDDD;).2. Added operator "in" for logical expressions in the statement "if". For example, expression x in ["a","b",1,2] return 1, if value of x equals "a","b",1 or 2, and else 0.
3. Set of letters in regular expression \w extended with Cyrillic letters.
4. Fixed some minor bugs of GUI.
5. Added check for updates.
Version 2.1.6, August of 2010
1. Added new functions:
isnull(x) to check that expression x fails or has not any value;notnull(x) to check that expression x does not fail or has some value;get_csv(s,delim) to get list of comma-separated-values (CSV) from string s;ltrim(s,c) to cut from string s leading characters defined by set c.2. Fixed bugs in following functions:
listfiles(s,i) for cases of long paths with white spaces;getname(s) for cases when filename contains one or more dots (.);getext(s) for cases when filename has empty extension;close_output() - value of @output was not cleared after function's call.3. Changed utility's GUI:
Version 2.1.7, January of 2011
1. Added new functions:
lfind(L,x) to find an element of a list L with value x;close_input() to close and stop processing of current input file.2. Fixed bug of incorrect displaying of cyrrilic filenames in output window (GUI).
3. Synchronized order of characters in macro-definitions @cp1251 and @cp866.
Version 2.1.8, December of 2011
1. Fixed bug of processing for mode of skipping body of HTML-tags (option skipTags).
2. Search process was optimized and as a result processing performance is highly increased. Particulary, you can see this when process files with very long lines. In this case performance increase is guaranteed as 10^N (N>2).
3. Added and slightly optimized examples.
Version 3.0, May of 2012
1. Refactored and optimized the console module of utility. This provides increasing of performance in the case of processing files with extra long lines.
2. Added support of script files in UTF-8. However GUI doesn't render UTF-8 characters properly the processing is done correctly.
3. Removed deprecated option "tagExceptions" which defined a list of paired tags, content of which should be skipped while processing. Such list can be defined by standard means with help of start and stop markers.
4. Added new functions:
get_length(s) calculates length of string in characters (rather then in bytes); string may include NCR and named HTML-entities;hex2int(s) converts hexadecimal code to integer, for example hex2int("ff") return 255;utf2str(s) converts UTF-8 string to ANSI (uncovertable characters coded as Unicode NCR and HTML named entities);str2utf(s) converts ANSI string to UTF-8;ncr2char(i) converts decimal Unicode NCR to ANSI-character; this function replaced obsolete function unicode(i);ncr2utf(i) converts decimal Unicode NCR to UTF-8 character.5. Added two auxiliary tools:
Version 3.2, November of 2012
Release of next version 3.1 was planned on October but then postponed and instead it the version 3.2 was prepared.
1. Fixed bug due which the debug mode in version 3.0 was switched off.
2. Fixed bug of empty value of @body macro when start and stop markers define beginning @bol and end of line @eol.
3. Added processing mode of data in UTF-8 encoding (switch -u). Using of regular expressions and case insensetive search were adopted for this mode too.
4. Fixed bug in function utf2ncr(s) for 3 and 4-bytes UTF-8 characters.
5. Added new functions:
utf8_upper(s) converting UTF-8 string to "upper case" (capital letters);utf8_lower(s) converting UTF-8 string to "lower case" (small letters).6. GUI was ported from Delphi 7 to open-source Lazarus IDE.
Version 3.3, January of 2014
1. Fixed function utf_upper(s).
2. Added new functions:
dir_exists(s) checking if specified directory exists and writable;make_dir(s) creating a directory if it doesn't exist;set_output(s) redirecting of output results to the specified directory;set_encoding(s) setting the encoding of processed files (ANSI/UTF-8);add_input(s) adding a file to the list of processed files;open_input(s) open specified file as a current input;load_script(s) open specified file as a current processing script;execute_processing(L) processing of specified list of input files by current script.3. Added macro @script, which returns the specification of current processing script.
4. Implemented an easy mechanism of step-by-s tep processing of input data.
Version 3.4, July of 2014
Unicon Programming Language was choosed as a programming environment instead of Icon. This move was done as Unicon is a next generation of Icon and currently dynamically developing. Unlike Icon it completly supports Windows OS. A few updates of Icon have been realised exclusively for POSIX/UNIX systems (including Cygwin for Windows). Version of Icon compiler used by xMarkup for MS Windows was realesed at 1997 and so is very ancient. As Icon code is 100% compatible with Unicon the language move was easy and hasn't require any changes. Moreover the using of Unicon for MS Windows provides performance speedup about 30% (in the case of Windows7/8 and modern "hardware" to 40-45%). Additionally Unicon greatly extends the features of xMarkup, for example:
I should note however, what the using of all these opportunities requires some redeveloping of xMarkup. This will be done in the next releases only.
Version 3.5, February of 2015
-i which outputs list of features supported by current implementation of utility.replace(s,s0,s1) which replaces all instancies of substring s0 in string s to s1.listfiles(s,i), which returns list of filenames by filesmask s. Unicon vs Icon implements own cross-platform means to process file system and directories, so this function was competely rewritten.Version 3.6, June 2015
-x of CLI.replace_first(s,s0,s1) to replace at string s only the first substring s0 to s1.rand(x) to generate pseudo random value.oldcyr2rus(s,l) to translate cyrillic UTF-8 text in old (pre-reform) orphography to modern syle.xm2exe.Version 4.0, August 2016
graphics, encoding, untranslatedRead, untranslatedWrite.Hist of histogram visualization.PlotWords to visualize words in the text.wt, which implements the interface with module wordtabulator of text analyse.Gauss to generate pseudo random value of Gaussian distribution.set_option to specify the needed option of processing, see chapter 4.4.initialize procedure.xm2exe and xmcomp.Version 4.1, January 2017
compatibility, which defines the minimum compatibility version of the script.Version 4.2, June 2017
Version 4.5, September 2020
Version 4.6, April 2022
Version 4.7, May 2023
ExtractDate extract date value from a string.str2date convert string to date value by defined format mask.date2str convert date to string by defined format mask.IsLeapYear check if year is a leap.julian compute Julian Day Number (see https://en.wikipedia.org/wiki/Julian_day).unjulian convert Julian Day Number to a date.dateGt compare two dates on greater then.dateLt compare two dates on less then.dateEq compare two dates on equality.dateBetween check if date belongs to defined interval.gregor2julian convert date of Gregorian calendar (new style) to Julian calendar (old style).julian2gregor convert date of Julian calendar (old style) to Gregorian calendar (new style).date_output to output date value (which is represented by record date_rec).Replace to replace substring in a string by defined regular expression.Script of processing rules (parameters file) includes a few sections, in which the search criteria, text transformation templates and other optional parameters are defined. Each section starts by predefined name in square brackets []. Section names are case insensitive. The list and order of sections in the script are arbitrary. In some cases script may contain just only single section [macros] or [procedures], or just single procedure main(). In the last case script will be the same as any Icon/Unicon sources.
Parameters file can include remark lines, which begin with sharp (#) or semicolon (;) character. Comment lines in the befinning of script form its header. Any number of empty lines can be inserted to improve the readibility.
Start marks describe the search templates for beginning of text elements, which should be processed. Start mark can be defined by string, character set or position in the current source file or line. Predefined macro-definitions can be used to define the start marks too.
The list of alternative start marks is defined in the section [startEntity], for example:
[startEntity] ; to find elements beginning with any digit @digits ; to find HTML-tag "title" <title> ; to find elements beginning with double space @space@space |
Stop marks describe the search templates for ending of text elements, which should be processed. Stop mark can be defined by string, character set or position in the current source file or line. Predefined macro-definitions can be used to define the stop marks too.
The list of alternative stop marks is defined in the section [stopEntity], for example:
[stopEntity] @sp </title> @null |
Transformation templates describe the conversion procedures of found text elements. Each transformation template is a string, which value is substituted instead of found text element (that is the text between start and stop marks). Transformation template can include both static and dynamic values, which are defined with help of various macro-definitions.
The list of transformation templates is defined in the section [startMarkup], for example:
[startMarkup] @start<font color="red">@body</font>@stop @null @space |
Optional section [stopMarkup] can be used to define a single post-transformation, which should be performed after each transformation defined in [startmarkup] section.
With help of options various working modes and parameters of the utility are defined. Options are described in the optional section [Options]:
| Parameter | Description |
minBodyLen = i |
minimum length of text between start and stop markers (default 0); |
counterInit = i0,i1,... |
list of initial values of internal counters (default all 1's); |
counterIncr = i0,i1,... |
list of increments of counters (default all 1's); |
counterType = {REL|ABS} |
type of counters type: REL defines reset all counters to initial values when each source file is opened; |
autoIncr = {true|false} |
if true then value of counter is automatically incremented on each call of macro-definition @counter(); |
ignoreCase = {true|false} |
if true then search of start and stop markers is case insensitive; |
skipTags = {true|false} |
if true then body of each HTML-tag is skipped; |
syncStop = {true|false} |
if true then the lists of start and stop markers are searched synchronously (to each start marker corresponds only one stop marker); else the start and stop markers are searched in any combinations; |
syncMarkup = {true|false} |
if true then the lists of start markers and transformation templates are processed synchronously (to each combination of the start-stop markers corresponds only one transformation template); else the first transformation template is used always; |
addNewLine = {true|false} |
if true then to the end of each source line the new line character is added; |
debug = {true|false} |
if true then debug output mode is defined to check the processing of source text. |
untranslatedRead = {true|false} |
defines read mode of untranslated byte-stream (versus standard line read). |
untranslatedWrite = {true|false} |
defines write mode of untranslated byte-stream (versus standard line write). |
encoding = {ANSI|UTF8} |
defines encoding of processed files. |
graphics = {true|false} |
defines graphical output mode in separate graphics window. |
compatibility = x.y.z |
defines minimum compatibility version of the script (beginning with version 4.1). |
The names of parameters are case insensitive. Any option can be defined from procedural body with help of set_option function.
If you need to skip while processing body of markup tags please define option skipTags=true.
Macro-procedures are defined in the optional section [Macros] or [Procedures]. The using of macros can be justificated when the special or not trivial text processing is needed.
Each macro-procedure begins with the title
| macro name |
or
| procedure name |
and ends with the line
| end |
The body of macro includes a set of statements on macro-language, which is described in the section
5. The macro is executed as a procedure and can return value, for example:
[Macros] macro increment # if current line begins with number n then return n+1 if i := many(@digits, @line)-1 then return numeric(substr(@line,1,i)) + 1 end |
Macro-procedures are called from transformation templates with help of macro-definition @run(), for example
[startmarkup] @start@run(name)@stop |
The names of functions and variables within body of macro are case sensitive! The types of variables are not explicit specified as in Icon but defined by current values. Together with user variables the macro-definitions can be used (as read-only variables) and counters' variables (counter, counterIncr, counterInit). The last ones are defined as arrays and can be recomputed, for example:
counter[1] := counterInit[1] counter[1] := counter[1] + counterIncr[1] |
Since version 1.8.0 two predefined macro-procedures "initialize" and "finalize" were introduced. Procedure "initialize" is executed automatically at the very beginning of processing (before any source file is open) and procedure "finalize" is executed at the end of processing (after closing the last source file). With help of "initialize" procedure you can initialize required variables, which shall be used during processing. With help of "finalize" procedure you can perform required actions after finishing the processing. These procedures are optional.
[macros]
procedure initialize
write("Beginning of processing...")
total := 0
end
procedure finalize
write("The end.")
write("total: ",total)
end
|
The language, which is used in macro-procedures is the simplicated dialect of the Icon Programming Language. The following features are supported:
- integer and real values arithmetic;
- string processing;
- variables, macro-definitions, lists and arrays;
- calls of all intrinsic Icon-functions;
- unary operators:
+ (absolute value)
- (negation);
- assignment:
:=
- binary arithmetic operators:
+ (addition)
- (substruction)
* (multyplication)
/ (division)
% (division by module)
^ (raise to power)
- string concatenation:
||
- relational operators for numeric values (returns 1 if true, else 0):
= (equality)
!= (non-equality)
< (less then)
<= (less or equal)
> (greater then)
>= (greater or equal)
- relational operators for strings (returns 1 if true, else 0):
== (equality)
!== (non-equality)
- relational operator for checking if value of x exists in X, where x - any variable or constant, and Х - table, set or list (array):
x in X
- compound statements in curly braces :
{}
- logical statements:
if-then
if-then-else
- loop statements:
while-do
every-do
- commentary lines beginning with character "#" or ";".
Described language features were implemented with help of program icalc.icn by Stephen B. Wampler. This program is included in Icon Program Library and intended to simulate infix desk calculator. The brilliant ideas implemented in icalc.icn allowed to use it as a basement for next enchancments and additions. Finally the idea to use it for macro-procedures came. The results are very fruitful.
Those who wants to learn more about features of Icon language can read the nice book of Ralph Griswold The Icon Programming Language. Ralph Griswold was author of Icon, he has gone in 2006.
On page unicon.org/ubooks.html there is a library with free books in PDF format devoted to Unicon Programming Language.
An excellent docset Unicon Programming prepared recently by a participant of Unicon Project, Brian Tiffin.
Statement ::= Expression | If | Loop | Return | Block-of-Statements
Block-of-Statements ::= { List-of-Statements }
List-of-Statements ::= Statement | Statement ; List-of-Statements
If ::= if Expression then Statement Else
Else ::= else Statement | ""
Loop ::= While_loop | Every_loop
While_loop ::= while Expression do Statement
Every_loop ::= every Expression to Expression do Statement
Return ::= return { Expression | "" }
Expression ::= Condition | Variable := Expression
Condition ::= Term {= | != | < | > | >= | <= | == | !== | in } Term | Term
Term ::= T { + | - } Term | T
T ::= F { * | / | % } T | F
F ::= E ^ F | E
E ::= L | { + | - | || } L
L ::= Function | Variable | Constant | ( Expression ) | String | Character-Set | Macro-definition | List
Fucntion ::= Identificator ( List-of-arguments )
Variable ::= Identificator | Identificator[ Expression ]
Constant ::= integer or real number
String ::= "string"
Character-Set ::= 'string'
Macro-definition ::= &Identificator | @Identificator
List ::= [ List-of-arguments ]
List-of-arguments ::= "" | Expression | Expression , List-of-arguments
|
Each statement of macro-language is written on the separate line and can not be continued on the next lines. Exclusion is a block of statements in curve brackets, which can be written on the many sequental lines. Each statement in the block should be ended by character semicolon (;).
All variables used in macro procedures are global. It means that their values are stored after completion of the macro. And moreover these values are common for all macros. The variable types are not explicit specified as in Icon but defined by current values. The names of variables and functions are case sensitive.
The short description of the most used functions of Icon is presented below. For each function the types of input parameters and results are given. The next signs are used:
N - natural number; i - integer; r - real; s - string; c - character set; L - list of values (array); x - any value; f - file descriptor.
The detailed description of all functions can be found on Icon home page in Arizona University https://www.cs.arizona.edu/icon/.
Unicon's official site unicon.org/ubooks.html represents a library of free books (in PDF format) about Unicon Programming Language.
abs(N) : N |
computes absolute value of N |
acos(r1) : r2 |
computes arc cosine |
asin (r1) : r2 |
computes arc sine |
atan (r1,r2) : r3 |
computes arc tangent of r1/r2 |
cos(r1) : r2 |
computes cosine |
dtor(r1) : r2 |
converts degrees to radians |
rtod(r1) : r2 |
converts radians to degrees |
exp(r1) : r2 |
computes exponential value |
iand(i1,i2) : i3 |
computes bitwise "and" |
icom(i1) : i2 |
computes bitwise complement |
integer(x) : i |
converts x to integer value |
ior(i1,i2) : i3 |
computes bitwise "inclusive-or" |
ishift(i1,i2) : i3 |
shifts bits |
ixor(i1,i2) : i3 |
computes "exclusive-or" |
log(r1,r2) : r3 |
computes logarithm |
numeric(x) : N |
converts x to numeric value |
real(x) : r |
converts x to real value |
sin(r1) : r2 |
computes sine |
sqrt(r1) : r2 |
computes square root |
tan(r1) : r2 |
computes tangent |
any(c,s) : i |
checks if the first character of string s belongs to defined set of characters c; returns 1 if true else fails |
сset(s) : с |
converts string s to a set of characters c |
center(s,i) : s2 |
centers line s by width i |
left(s,i) : s2 |
shifts string s to left by width i |
left(s1,i,s2) : s3 |
produces a string of size i in which s1 is positioned at the left, with s2
used for padding at the right if necessary; for example, left("abc",5,"+") returns "abc++" |
right(s,i) : s2 |
shifts string s to right by width i |
right(s1,i,s2) : s3 |
produces a string of size i in which s1 is positioned at the right, with s2
used for padding at the left if necessary; for example, right("abc",5,"+") returns "++abc" |
ord(s) : i |
returns decimal code of character |
char(i) : s |
returns character by decimal code |
find(s1,s2) : i |
searches substring s1 within string s2; returns start position of s1 in s2 else fails |
map(s1,c1,c2) : s4 |
translates characters of string s1, which belong to set c1, into corresponding characters of set c2 |
many(c,s) : i |
checks if initial characters of a string s belong to a set c; returns position of the first character in s, which doesn't belong to c, else fails |
match(s1,s2) : i |
checks if start of string s2 equals to substring s1; returns 1 if true else fails |
upto(c,s) : i |
searches in a string s characters from a set c; returns position of character else fails |
repl(s,i) : s2 |
replicates string s i times |
reverse(s) : s2 |
reverses string s |
string(x) : s |
converts value x to a string |
trim(s) : s2 |
truncates right trailing spaces from a string s |
trim(s, c) : s2 |
truncates right trailing symbols defined by set c from string s |
Note: fail-interruption leads to rollback of execution of current operator. This behaivour is defined by operating logic of Icon language, which supports the backtracking (as in Prolog). If current statement fails it means that the statement is just not executed. For example, the following code will fail because string "qwerty" is not began with "123", so variable i will not get any value:
...
i := match("123", "qwerty")
write(i)
...
|
list(i,x) : L |
creates list of length i with values x |
pop(L) : x |
pushes the initial value from a list |
get(L) : x |
the same as pop(L) |
pull(L) : x |
pushes the last value from a list |
push(L,x1,x2,...,xn) : L |
adds values to a list with the beginning |
put(L,x1,x2,...,xn) : L |
adds values to a list with the end |
sort(L) : L |
sorts a list L and produces sorted list of its values |
sortf(L,i) : L |
sorts a list by i-th field, provided that elements of source list are lists two |
sortfiles(L) : L |
sorts a list of files L in the order of path and name |
asort(L) : L |
sorts a list of strings in alphabetical order: output strings are converted to lowercase with first letter to capital |
set(L) : S |
creates a set from a list L (in a set all values are unique) |
sort(S) : L |
sorts a set S and produces sorted list of its values |
table(x) : T |
creates table T, keys of which are initiated by value x |
table() : T |
creates table T, keys of which are initiated by null value |
insert(T,x) : T |
inserts into table T key x; statement T[x] := y defines value y to key x |
delete(T,x) : T |
deletes from table T key x |
member(X,x) : x |
checks if table T contains key x; returns x if so or fails |
sort(T,i) : L |
sorts a table and produces sorted list, each value of which is a list of pair values (key,value) of source table. If i=1 then table is sorted by keys, if i=2 then by values. |
close(f) : f |
closes open file f |
getch() : s |
reads character from keyboard |
getche() : s |
reads character from keyboard with echo |
kbhit() : n |
returns code of pressed key |
open(s,"r") : f |
opens file s to read (returns descriptor of file) |
open(s,"w") : f |
opens file s to write |
open(s,"a") : f |
opens file s to write in append mode |
read(f) : s |
reads next line from a file |
reads(f,i) : s |
reads file in buffer of length i |
remove(s) : n |
removes file s |
rename(s1,s2) : n |
renames file s1 to s2 |
seek(f,i) : f |
moves to i-th position of a file |
where(f) : i |
returns current position in a file |
write(x1,x2,...,xn) : xn |
writes the list of values with line termination sequence |
writes(x1,x2,...,xn) |
writes a list of values without of line termination sequence |
exit(i) |
exits from utility with status i |
chdir(s) : n |
change current directory to s |
setenv(s1,s2) |
sets value s2 of environment variable s1 (within current process) |
getenv(s1) : s2 |
returns value of environment variable s1 |
stop(x1,x2,...,xn) |
exits from utility and outputs to console defined list of values |
system(s) : i |
calls system program s |
type(x) : s |
returns symbolic type of value x |
ReFind(s1,s2,i1) : i |
find in string s2 substring s1 defined by regular expression (returns initial position of such substring in s2 else fail); if i1 specified then search starts with position i1 else with beginning of s2; special characters in s1 shall be defined by double \\, e.g. "\\w" instead of "\w" |
ReMatch(s1,s2,i1) : i |
find in string s2 substring s1 defined by regular expression (returns position after such substring in s2 else fail); if i1 specified then search starts with position i1 else with beginning of s2; special characters in s1 shall be defined by double \\, e.g. "\\w" instead of "\w" |
roman(i) : s |
converts decimal integer to Roman number: roman(21) returns "XXI" |
unroman(s) : i |
converts Roman number to decimal integer: unroman("XXII") returns 22 |
julian(date) | see here |
unjulian(date) | see here |
| Data processing operations | |
set_encoding(s) |
set data encoding of processed files (ANSI or UTF-8) |
set_option(s) |
define processing option, see chapter 4.4 |
load_script(s) |
load specified file as a current processing script |
execute_processing(L) |
processing of specified list of input files |
add_input(s) |
add specified file to the end of list of input files |
open_input(s) |
open specified file as a current input; this triggers @bof marker if it's defined |
read_input() : s |
returns next line of current source file (this line is excluded from processing) |
read_input(i) : L |
returns list of next i lines of source file; if i = 0, then returns all following lines to the end of file (this lines are excluded from processing) |
close_input() |
closes and stops processing of current input file; this triggers @eof marker if it's defined |
tabto(i) : s |
moves to k-th position of current processed substring @subject within source line. The first characters of string till position i are skipped from any processing. i=0 defines move to the end of source line. Negative values of i defines move from the end of line on i positions to beginning. |
eof() |
moves to the end of source file; this triggers @eof marker if it's defined |
set_output(s) |
redirecting data output to specified directory; if this directory doesn't exist it will be created |
open_output(s) |
open output file s; all current output will be redirected to this file |
close_output() |
closes current output file |
write_output(x1,...,xn) |
writes to output file a list of values |
Processing of HTML elements | |
diacritic(i) : s |
converts decimal code of ISO-8859-P1 character (diacritics) to named HTML-entity, for example, diacritic(192) returns "À" |
greek(i) : s |
converts decimal Unicode NCR for Greek to named HTML-entity, for example, greek(913) returns "Α" |
isEsc(s1) : s2 |
checks if s1 is HTML named entity or Unicode NCR, if so returns s1 else fails |
isTag(s1) : s2 |
checks if s1 is a name of HTML 4.0 tag, if so returns s1 else fails |
html2txt(s) : s |
converts SGML/XML/HTML content to a simple text |
get_htmltitle(s) : s |
returns title of HTML-document defined by url |
ncr2char(i) : с |
converts decimal Unicode NCR to ANSI character, for example, ncr2char(1040) for Russian locale returns Russian letter А (\xC0) |
ncr2utf(i) : s |
converts decimal Unicode NCR to multi-byte UTF-8 character |
Date processing | |
ExtractDate(str, fmt, months) : L |
extracts date from str by defined format fmt. The following elements maybe used in fmt:dd - sequential day number within month,mm - sequental month number,mon - name of month,yy | yyyy - sequential number of year.Optional parameter months defines list of month names (RE maybe used for that).Returns list of two elements: 1) extracted date as record date_rec with fields (year, month, day, yearday, monthname, dayname) and 2) extracted date value as a string.
For example, ExtractDate("There is 5 March 1953 year","dd mon yyyy") return [(1953,3,5,64,"Monday","March"),"5 March 1953"]. |
str2date(str, fmt, months) : R |
converts string str to date by defined format fmt. Optional parameter months defines list of month names. Return record date_rec with fields (year, month, day, yearday, monthname, dayname).
For example, str2date("23.5.1968","dd.mm.yyyy") return (1968,5,23,68,144,"Monday","May"). |
date2str(date, fmt, months) : s |
converts date to string by defined format fmt. Optional parameter months defines list of month names. Date is encoded as record date_rec with fields (year, month, day, yearday, monthname, dayname). |
dateGt(d1, d2): int |
compares if date d1 greater then date d2; returns 1 or fails. |
dateLt(d1, d2): int |
compares if date d1 less then date d2; returns 1 or fails. |
dateEq(d1, d2): int |
compares if date d1 equals date d2; returns 1 or fails. |
dateBetween(d, d1, d2): int |
compares if date d belongs to interval (d1,d2); returns 1 or fails. |
gregor2julian(d): d |
converts date of Gregorian calendar (new style) to Julian calendar (old style). |
julian2gregor(d): d |
converts date of Julian calendar (old style) to Gregorian calendar (new style). |
date_output(date) |
outputs date represented by record date_rec with fileds (year, month, day, yearday, monthname, dayname). |
IsYearLeap(year) : i |
checks if year is a leap? Returns 1 for leap year or fails. |
julian(date) : i |
computes Julain Day Number for defined date, which is represented as record date_rec with not empty fileds (year, month, day).
For example, julian(str2date("23.5.1968","dd.mm.yyyy")) return 2440000.See https://en.wikipedia.org/wiki/Julian_day |
unjulian(i) : R |
computes date by Julain Day Number; returns date as record date_rec with fileds (year, month, day, yearday, monthname, dayname).
For example, unjulian(2440000) return (1968,5,23,144,"May","Thursday"). |
String processing | |
get_csv(s,delim) : L |
returns list of values L, extracted from CSV-string s (comma-separated-values); delim by default defines delimeter as fixed string-value (e.g. ","); to define delim as set of characters you may use function cset (e.g. cset(",;\t")) |
get_length(s1) : i |
calculates length of string in characters (rather then bytes); string may include NCR and named HTML-entities |
length(x) : i |
returns length of string in bytes or size of structure x |
len(x) : i |
the same as length(x) |
like(s1,s2) : i |
returns 1 if string s1 satisfies to search mask s2 else fails. Search mask may include asterisk (*), which defines any string sequence, and underscore (_), which defines any single character. For example, like("example", "e*a*e") returns 1. |
likeword(s) : i |
returns 1 if string s likes to a word within current line else fails |
lower(s1) : s2 |
converts string s1 to lower case |
ltrim(s1) : s2 |
cut from string s1 leading white spaces |
ltrim(s1,c) : s2 |
cut from string s1 characters defined by a set c |
replace(s,s0,s1) : s2 |
replaces all instancies of substring s0 in string s to s1 |
replace_first(s,s0,s1) : s2 |
replaces first instance of substring s0 in string s to s1 |
Replace(s,s0,s1) : s2 |
replaces all instancies of substring s0 in string s to s1 with help of RE.
For example, Replace("8th Narch", "\\dd(\\dd)?th", "\\dd(\\dd)?") returns "8 March". |
sql_quotes(s1) : s2 |
replaces every single apostrophe character (') within a string on double apostrophes ('') |
substr(s1,i1,i2) : s2 |
returns substring beginning with i1-th character of string s1 and length i2; if i2 missed then till the end of string s1 |
str2utf(s1) : s2 |
converts ANSI string to UTF-8 |
upper(s1) : s2 |
converts string s1 to upper case |
utf2ncr(s) : s |
converts UTF-8 string to string of NCR Unicode characters (&#DDDD;) |
utf2str(s1) : s2 |
converts UTF-8 string to ANSI (uncovertable characters coded as Unicode NCR and HTML named entities) |
utf8_upper(s1) : s2 |
converts UTF-8 string to "upper case" (capital letters) |
utf8_lower(s1) : s2 |
converts UTF-8 string to "lower case" (small letters) |
File operations | |
dir_exists(s) : i |
check existence of directory s; returns 1 if it exists and writable else 0 |
make_dir(s) : i |
make directory s if it doesn't exist |
file_exists(s) : i |
checks existanse of file s; returns 1 if file exists else 0 |
get_content(s) : L |
returns list of all non-empty lines of file s (the same as @read(s)) |
getext(s1) : s2 |
extracts type from file specification s1, for example on UNIX getext("/home/work/file.txt") returns "txt" |
getname(s1) : s2 |
extracts name from file specification s1, for example on UNIX getname("/home/work/file.txt") returns "file" |
getpath(s1) : s2 |
extracts path from file specification s1, for example on UNIX getpath("/home/work/file.txt") returns "/home/work/" |
get_separator() : c |
returns system character-separator used in the file paths |
listfiles(s,i) : L |
returns a list of files, which satisfy to search mask s; second parameter is optional - if it equals 1 then search of files is perfomed recursively in all nested folders |
Graphics operations | |
Hist(T, title, options) |
visualizes histogram defined by structure T (table or list). If T is a list, then each its value must be a 2(or 3)-dimensional list (array): first value is a word, second one is a frequency (rank) and optional third is a color. Optional parameter title defines the title of graphical window. options is a string of histogram's options, see chapter 8.20 for details. |
PlotWords(T, title, options) |
visualizes a set of words defined by structure T (table or list). If T is a list, then each its value must be a 2(or 3)-dimensional list (array): first value is a word, second one is a frequency (rank) and optional third is a color. Optional parameter title defines a title of graphical window. options is a string of plot options, see chapter 8.21 for details. |
Other operations | |
hex2int(s) : i |
converts hexadecimal code to integer, for example hex2int("ff") return 255 |
lfind(L,x) : i |
find element of list L which has value x; returns index of such element or 0 |
EOL(s) : s |
set/get end-of-line (EOL) format: EOL("WIN") or EOL("\xD0\xA0") for Windows; EOL("UNIX") or EOL("\xA0") for Unix; EOL("MAC") or EOL("\xD0") for Mac; EOL() returns current EOL |
isnull(x) : i |
returns 1 if expression x fails or has not any value, else 0 |
notnull(x) : i |
returns 1 if expression x has any value else 0 |
rand() : r |
returns pseudo random value at interval (0.0,1.0) |
rand(n) : i |
returns pseudo random value at interval (1,n) |
Gauss(m,f) : r |
returns pseudo random value of Gaussian distribution (m-mean value, f-standard deviation). This function based on function gauss.icn from IPL library |
wt(L1,L2,L3) : L |
returns list of words extracted from text corpus; this is an output of module wordtabulator of text analysis. L1 defines list of input texts. Optional parameter L2 defines list of texts exclusions. Optional parameter L3 defines list of processing options. |
The counters are used when the dynamic markup should be created, which content is defined by sequental numbers of the processed text elements. For example, with help of counters the navigation hyperlinks can be generated for a set of html-documents, the names of which includes sequental numbers.
The number of counters is not limited and their parameters (initial value, type and increment) are defined in the section [Options]. The counters can be of two types - relational and absolute. Relational counters vice verse of absolute ones are automatically initialized when the next source file is opened for processing.
The values of i-th counter can be substituted within transformation template
with help of macro-definition @counter(i) or assigned in macro procedure
by variable counter[i]. The macro-definition @counter(i)
substitutes the current value of i-th counter and, if the auto increment mode is enabled (autoincr=true) then
automatically increments it. When auto increment mode is disabled (autoincr=false)
the incrementing of i-th counter can be defined in transformation template
with help of macro-definition @next(i). This macro-definition doesn't substitute any value
but only performs incrementing of counter. In macro procedure the incrementing of counter can be executed with help of
statement:
counter[i] := counter[i] + counterIncr[i]
To perform manual initializing of i-th counter within transformation template
the macro-definition @reset(i) can be used. This macro-definition doesn't substitute
any value but resets the counter to initial value.
In macro procedure the initializing of counter can be executed with help of
statement:
counter[i] := counterInit[i]
Macro-definitions can be used within start and stop markers, transformation tempaltes or procedural macros. Macro-definition is used to define string value, set of characters or position in source file/line.
@ascii |
set of 128 ASCII-7 characters |
@blank |
a list of blanks [@sp, @tab, " "] |
@body |
substring between start and stop marks |
@bof |
beginning of source file |
@bol |
beginning of source line |
@call s |
performs execution of macro-procedure s from body of other macro-procedure; it's not a true "call" but a kind of code inclusion |
@clcase |
set of 33 lowercase Cyrillic letters in Win-1251 encoding |
@cletters |
synonym of @cp1251 |
@clock |
value of current time in format "HH:MM:SS" |
@counter |
current value of first counter; you can't use it in macro-procedures and @eval() |
@counter(i) |
current value i-th counter; you can't use it in macro-procedures and @eval() |
@cp1251 |
set of Cyrillic letters in Win-1251 encoding |
@cp866 |
set of Cyrillic letters in DOS-866 encoding |
@cset |
set of 256 ASCII-8 characters |
@cset(s) |
set of characters defined by string s |
@cucase |
set of 33 capital Cyrillic letters in Win-1251 encoding |
@date |
value of current date in format "YYYY/MM/DD" |
@dateline |
full value of current date |
@digits |
set of digits {0-9} |
@eof |
end of source file |
@eol |
end of source line |
@e |
value of number e = 2,71... |
@eval(s) |
evaluates and substitutes value of expression s |
@include file |
includes content of the specified file to body of macro-procedure |
@features |
list[] of features supported by current version of xMarkup |
@file |
specification of source file |
@fileno |
sequental number of source file in a list of processed files |
@host |
name of your computer |
@input |
specification of source file (synonym of @file) |
@INPUT |
list of ALL input files |
@letters |
set of Latin letters |
@lcase |
set of 26 lowercase Latin letters |
@line |
value of source line |
@lineno |
sequental number of source line in processed file |
@next(i) |
generates next value of i-th counter |
@nfiles |
total number of processed files |
@nl |
new line character |
@null |
empty value |
@output |
specification of output file |
@OUTPUT |
list of ALL output files generated during the current run (this list is growning during time) |
@pi |
value of number pi = 3,14... |
@pos |
position of offset in substring @subject, which defined with help of tabto(i) |
@q |
character of double quotes (") |
@read(s) |
returns list of all not empty lines of file s (name of file is defined without quotes) |
@regexp(s) |
search template in a form of regular expression s |
@reset(i) |
resets i-th counter to initial value |
@run(s) |
executes macro-procedure s and substitues returned value |
@script |
specification of current processing script |
@stepno |
sequental number of current processing step (started with 0 and increments by each execute_processing call) |
@source |
set of input files, defined by command line's parameter -f or procedure set_input() |
@semicolon |
character of semicolon (;) |
@space |
character of white space or tab |
@sp |
white space (synonym of @space) |
@start |
value of current start mark |
@stop |
value of current stop mark |
@subject |
rest of current processed line, a substring between current stop mark and end of line |
@tab |
tab character |
@target |
path of output files as defined by command line's parameter -o or procedure set_output() |
@time |
current elapsed time of processing in milliseconds |
@ucase |
set of 26 capital Latin letters |
@version |
current version of xMarkup |
Examples how to use macro-definitions:
| i := match(@space,@line) | returns 1 if current line begins on white space else fails |
| i := any(cset("abc"),@line) | returns 1 if source line begins on letters "a","b" or "c" else fails |
| i := upto(@ucase,"an ExamplE") | returns position (4) of first uppercase letter in a string |
| i := many(@ucase,"an EXample") | returns position (6) after beginning sequence of uppercase letters |
| s := map(@line,"abc","123") | translates characters "a","b","c" of source line to "1","2","3" |
| ( @lineno <= 10 ) | true for first ten lines of processed file |
| like(@line,"Ah*!") | true for source lines, which begins on "Ah" and ends by exclamation mark (!) |
| s := tabto(0) | moves to the end of source line (it means that rest of source line remebered in s is skipped from processing) |
Note. Macro-definitions, which return a set of values or position can not be used in the transformation templates (except of @read(s)). Names of macro-definitions are case sensitive.
Macro-definition of the null string @null can be used in three cases.
1. To define markers, which begin with sharp (#), semicolon (;) or opening square bracket ([) characters, which are used to define the comment lines or sections. For example,
[startEntity] ; marker is started with sharp character @null#01 ; marker is started with semicolon @null;01 ; marker is started with opening square bracket @null[01] |
2. To define search by one marker only (start or stop). For example, searching of "abc" can be defined as:
[options] syncStop = true [startEntity] abc [stopEntity] @null |
or
[options] syncStop = true [startEntity] @null [stopEntity] abc |
3. To define start/stop markers. That is if markup template is defined as @null then substring <start-marker><body><stop-marker> will be removed from the output text.
Special characters are used within string values (in procedural macros) and defined as 2-character sequence beginning with character of backward slash (\).
| \\ | backward slash |
| \" | quote character |
| \q | the same as \" |
| \n | new line character (the same as @nl) |
| \t | tab character (the same as @tab) |
| \r | caret's return character |
| \f | line feed character |
| \xnnn | character defined by heximal code nnn |
Example.
s := "\"this line will be outputted in quotes\"" write_output(s,"\n") |
Since version 2.0 of xMarkup start or stop marks can be defined with help of regular expressions. This feature was implemented with help intergartion of procedure regexp.icn, which author is Robert J. Alexander. This procedure is from Icon Public Library.
Regular expression is defined with help of macro-definition @regexp(s), for example: @regexp("[0-9]*\.[0-9]+"). Please see chapter Examples, in which usage of regular expressions is illustared in a few examples.
The regular expression format is very close to format supported by the UNIX "egrep" program, with modifications as described in the Perl programming language definition. Following is a brief description of the special characters used in regular expressions. In the description, the abbreviation RE means regular expression.
| c | An ordinary character (not one of the special characters discussed below) is a one-character RE that matches that character. | \c | A backslash followed by any special character is a one-character RE that matches the special character itself. |
| . | A period is a one-character RE that matches any character. |
| [string] | A non-empty string enclosed in square brackets is a one-character RE that matches any *one* character of that string. If, the first character is "^" (circumflex), the RE matches any character not in the remaining characters of the string. The "-" (minus), when between two other characters, may be used to indicate a range of consecutive ASCII characters (e.g. [0-9] is equivalent to [0123456789]). Other special characters stand for themselves in a bracketed string. |
| * | Matches zero or more occurrences of the RE to its left. |
| + | Matches one or more occurrences of the RE to its left. |
| ? | Matches zero or one occurrences of the RE to its left. |
| {N} | Matches exactly N occurrences of the RE to its left. |
| {N,} | Matches at least N occurrences of the RE to its left. |
| {N,M} | Matches at least N occurrences but at most M occurrences of the RE to its left. |
| ^ | A caret at the beginning of an entire RE constrains that RE to match an initial substring of the subject string. |
| $ | A currency symbol at the end of an entire RE constrains that RE to match a final substring of the subject string. |
| | | Alternation: two REs separated by "|" match either a match for the first or a match for the second. |
| () | A RE enclosed in parentheses matches a match for the regular expression (parenthesized groups are used for grouping, and for accessing the matched string subsequently in the match using the \N expression). |
| \N | Where N is a digit in the range 1-9, matches the same string of characters as was matched by a parenthesized RE to the left in the same RE. The sub-expression specified is that beginning with the Nth occurrence of "(" counting from the left. E.g., ^(.*)\1$ matches a string consisting of two consecutive occurrences of the same string. |
The following extensions to UNIX REs, as specified in the Perl programming language, are supported.
| \w | Matches any alphanumeric (including "_"). |
| \W | Matches any non-alphanumeric. |
| \b | Matches only at a word-boundary (word defined as a string of alphanumerics as in \w). |
| \B | Matches only non-word-boundaries. |
| \s | Matches any white-space character. |
| \S | Matches any non-white-space character. |
| \d | Matches any digit [0-9]. |
| \D | Matches any non-digit. |
Symbols \w, \W, \s, \S, \d, \D can be used within [string] REs.
You should understand that some regular expressions will produce different results for ANSI and UTF-8 data. This is due to that regular expressions implemented for ANSI encoding. ANSI data are encoded as 1 byte per character but UTF-8 data are always multi-byte (from 1 to 4 bytes per character). So, expression [А-яЁё] for ANSI defines cyrillic alphabet but it's not true for UTF-8. Instead of range you should explicitly define all letters [АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЧЦШЩЬЪЫЭЮЯабвгдеёжзийклмнопрстуфхчцшщьъыэюя] for UTF-8. The same warning for dot (.) which defines any single character. For UTF-8 it will produce correct result only for 1-byte characters (ASCII). However special symbols \b or \w for ANSI and UTF-8 will produce the same results always.
Macro-definition @subject defines a rest of current processed line, that is a substring between stop marker and end of line. Macro-definition @pos defines offset position in @subject (1 by default). Function tabto(i) produces move to offset position i. The move means that all characters between start of @subject till position i shall be skipped from processing (as would there is no such substring in a source line). If a whole line @subject shall be skipped then offset position defined as 0. Negative value of offset position means move to i-th position starting with end of line. For example, tabto(3) moves to third character of @subject; tabto(-1) moves to last character of line; tabto(-3) moves to third character from the end of line. See example 8.5, which demonstrates usage of tabto() function.
To get filling how to use these loops it will be usefull to show simple examples. Let's we have array or list of values, which we need to process in some way. For that we will use loop operator while or every - which we like.
In the case of while any expression, which return numeric value, may be used as logical condition. Check of condition gives true if value of expression is not equal 0 else false. For example,
# print list of values with help of while-loop array := ["a","b","c"] i := 0 while i < len(array) do write( array[i := i + 1] ) |
It could be strange but expression i < len(array) returns 1 if value of i less then length of array else 0. Such agreement is defined for any logical conditions. By the way, expression while 1 do ... defines endless loop.
Another example of while to process a list of values. In this case function get() is used. This function returns next element of a list and simultaneously pushes it from a list. After end of loop the source list will be empty.
# print list of values with help of while-loop array := ["a","b","c"] while len(array)>0 do write( get(array) ) # array now is empty |
When you choose to use every-loop you need to specify interval of integer numbers, which define length of a loop. For example, every 3 to 5 defines length 3 (for values 3,4,5). Any expressions, which return interger numbers, may be used as boundaries of a loop interval. Below is example of every-loop:
# print list of values with help of every-loop array := ["a","b","c"] i := 0 every 1 to len(array) do write(array[i := i + 1]) |
Files which are opened for read/write while processing from body of macro-procedures, for example:
procedure initialize
in := open("infile.txt", "r")
out := open("outfile.txt", "w")
...
# get array of file lines
t := get_content("infile.txt")
# or
t := list()
while notnull(s := read(in)) do put(t,s)
...
close(in)
end
|
by default are read/created by path of location of current markup rules' file. That is directory which locates file of markup rules always defines working directory. You may use relational paths which shall be specified relative to the working directory, Surely, you may use full paths - in this case files can be located anywhere. Mentioned above shall be applied also to macro-definition @read(file).
Text string s which contains characters of any national 2-byte encoding may be converted to other encoding with help of function map(s,srcenc,trgenc), where srcenc - a character set of source encoding, trgenc - a character set of target encoding. Using macro-definitions @cp1251 and @cp866, which define a set of cyrillic letters for Win-1251 and DOS-866 encodings you can:
# convert string s from Win-1251 to DOS-866 s := map(s, @cp1251, @cp866) # or convert string s from DOS-866 to Win-1251 s := map(s, @cp866, @cp1251) |
You can use function str2utf to convert ANSI string to UTF-8:
# convert string in Win-1251 encoding to UTF-8 s := str2utf(s) # convert string in Win-1252 encoding to UTF-8 s := str2utf(s,"windows-1252") |
The same script may be used for processing of different data, so it may be convinient for you to use parameters. Surely these parameters may be hard coded within script. But in this case you will need to modify the script every time. You can try a few ways to avoid doing this.
write("input value of P1=")
p1 := read()
write("input value of P2=")
p2 := read()
|
procedure initialize
@include \examples\param.txt
end
...
# included file may contain any expressions of macro-language:
p1 := 10
p2 := 2
|
> set p1=10
> set p2=2
> xm.exe -f*.html -ptest.par
# values of environment variables are read in script as:
p1 := getenv("p1")
p2 := getenv("p2")
|
Starting with version 4.1 you can define environmental variables passed to script directly at GUI.
Sometimes you should process your data files by different scripts through a set of sequental steps, for example,
Naturally, each step of such processing is quite simple to implement with help of a single script. But whole processing should be organized in such way that the results of previous step should be passed as input of the next step. When number of steps becames big the organization's complexity of such processing is also increasing. At version 3.3 of xMarkup the simple mechanism of step-by-step data processing with unlimited number of steps was introduced. To do this you should sequentely do following:
In call of execute_processing() you need to define one required parameter - a list of files to process. The universal approach how to construct such list with help of output redirecting of processing results is shown below. All you need to do, is
FILES within procedure initialize;set_output() redirect output to defined directory and then add specification of current output to FILES list.Example:
# script step01.par (step #01)
#
[startentity]
@bof
...
[startmarkup]
@run(bof)
...
[options]
syncStop=true
syncMarkup=true
[macros]
procedure initialize
FILES := []
end
procedure bof
# redirect output for current processed file to defined directory
set_output("d:\\work\\data\\step01")
# add specification of current output file (redirected) to the list FILES
put(FILES, @output)
end
...
procedure finalize
# define encoding of data files on the next step
set_encoding("UTF-8")
# load script of the next step, step02.par
load_script("step02.par")
# pass control to this script and start processing of output files of current step
execute_processing(FILES)
end
|
Starting with version 3.4 as a benefit of using Unicon Programming Language the utility became capable to use databases. Access to target database is performed through appropriate ODBC driver. In the case of MySQL database installation of ODBC driver and its configuration for different platforms are described in details in on-line documentation.
Let's suppose we configured data source with name mysql, username user01 and password 123. You can check access to this data source with help of following simple script:
[Macros]
procedure initialize
if notnull(db := open("mysql","o","user01","123")) then write("Successfuly connected!") else stop("Failed to connect!")
close(db)
exit(0)
end
|
Working with databases from Unicon using SQL query language is well described in the book Programming with Unicon. Also see the examples 8.18 and 8.25.
Since version 4.0 xMarkup was integrated with text analysis module, which initially was developed within project wordTabualtor. Because author got thougts that developing wordTabulator as standalone project has no sense.
Now You can make text analysis right from xMarkup script by calling function wt(F, E, opts), where
Function wt returns list of found words (text elements) and their frequencies. Each element of the list is a pair of values: (word, frequency).
You can red detailed description of all options at WordTabulator. User's Guide. As rare exclusion all these options were ported to xMarkup.
Each option is defined as a string parameter=value:
Note. Options with * mark at beginning maybe defined more one time.
Author hopes that in near future new GUI for wordTabulator module will be implemented.
See examples 8.20 and 8.21 of using wordTabulator module.
The utility works as a kind of finite states machine. The instructions to the machine are defined by search conditions and transformation rules described in the script of processing rules. On the input is given a source text, on the output the results of its transformation are put. Let us describe the general algorithm of text processing implemented in the utility:
| 1. | Open the next file from a list of source files. If the list is empty then finish. |
| 2. | Read the next line from the file and go to its beginning position. If the end-of-file is reached then return to step 1. |
| 3. | If the end-of-line is reached then return to step 2. |
| 4. | From the list of start marks choose the mark, which is closest to current position and has maximum length. If no start mark can be found in the current line then return to step 2. |
| 5. | Move to position after the start mark and output text before it "as-is". |
| 6. | If defined syncStop=true then seek starting with current position the stop mark,
which has the same sequental number in a list as the found start mark. Else from a list of stop marks choose one,
which is closest to current position. |
| 7. | In the case of successful execution of step 6 go to step 8. Else read the next line, go to its beginning and then return to step 6. |
| 8. | If defined syncMarkup=true then choose transformation template,
which has the same sequental number in a list as the found start marker.
Else choose the first template in a list. Transform and output text according to transformation template then move to position after the stop mark and
return to step 3. |
During searching of the start or stop marks their priority is taken into account. It means that the mark with higher priority
will be choosen in the case of other equal conditions.
Let us enumerate marks in the descent order of their priority:
Below is a list of limitations:
1. Start mark should be located a whole in a source line, else it will not be found.
2. Stop mark should be located a whole in a source line too.
3. Definition of start or stop mark may include only one macro-definition in the case of character set.
And moreover nothing else can be set in such definition. For example, definition
@digits@letters is wrong. This limitation is very easy to eleminate by using
of procedural macros.
4. Statement if ... then ... else ... should be written in a single line. This limitation may be work arounded with help of block structure:
if i = 1 then s := "one" else {
if i = 2 then s := "two" else {
if i = 3 then s := "three" else s := ""
}
}
}
|
5. It is impossible to use logical operators "or", "and", "not" to construct logical expressions.
6. Value of expression used in operator "if" or "while" as a checked condition shall be integer (0 corresponds to false, 1 - true). For example, expression
while s := read() do write(s)
will produce Run-time error when value of string s is not a number. To check end of reading you shall use function notnull:
while notnull(s := read()) do write(s).
7. Macro-definition @bof may be used only for start mark.
8. As utility is a "double" interpreter (Icon binary is a byte-code itself) its performance by definition is much slow than C or C++ programs.
The print-outs of scripts are provided below to show how text may be processed by xMarkup.
See example 8.9, which shows as a list of HTML-tags may be generated.
# conv2txt.par
# Removes any XML/SGML/HTML markup
[startEntity]
@regexp("<(no)?script")
@regexp("<(/)?(\w)+")
<!doctype
<!--
[stopEntity]
@regexp("</(no)?script>")
>
>
-->
[startMarkup]
@null
[Options]
syncStop = true
ignoreCase = true
|
# compact.par # Purge empty lines [Options] addNewLine = false [startEntity] @bol [stopEntity] @eol [startMarkup] @eval(if len(trim(@line,' \t')) > 0 then @line||@nl) |
# headers.par # Insertion of header and footer to text. [StartEntity] @bof @eof [StartMarkup] <!-- This is a header of @file -->@nl <!-- This a footer of @file --> [Options] syncMarkup = true |
# Markup of words in sentence with help of regular expressions.
# Sentence ends with point (.), exclamation mark (!) or question mark (?).
# Symbol \b defines word boundary - that is beginning or end of the line, punctuation mark or space.
# Symbol \w defines any alpha-numeric character.
[startentity]
@regexp("\b\w+")
@regexp("[\.!?]")
[startmarkup]
@run(word)
@run(end_of_sentence)
[options]
syncMarkup=true
[macros]
macro initialize
sentence_counter := 0
word_counter := 0
is_end_sentence := 1
end
# next word found
procedure word
# if we at the beginning of sentence
if is_end_sentence then {
sentence_counter := sentence_counter + 1
word_counter := 0
write("<sentence id=\"",sentence_counter,"\">")
}
word_counter := word_counter + 1
write("<word id=\"", sentence_counter, ".", word_counter, "\">", @start, "</word>")
is_end_sentence := 0
end
# we are riched the end of sentence
procedure end_of_sentence
write("</sentence>")
is_end_sentence := 1
end
|
Mommy watches TV, Daddy drinks wine, children are playing. |
<sentence id="1"> <word id="1.1">Mommy</word> <word id="1.2">watches</word> <word id="1.3">TV</word>. <word id="1.4">Daddy</word> <word id="1.5">drinks</word> <word id="1.6">wine</word>. <word id="1.7">children</word> <word id="1.8">are</word> <word id="1.9">playing</word> </sentence> |
# trim.par # Purging of long spaces [StartEntity] @regexp([\s]+$) @regexp([\s]+) [StartMarkup] @null @sp [Options] syncmarkup=true |
In this example a set of source files are merged to a single output file, name of which is prompted to enter (by default "unite.dat"). After completion of processing the number of lines written to output is displayed. With help of this example you can understood how useful may be procedures initialize и finalize.
# unite.par
# Merging of text files to a single one
[StartEntity]
@eol
[StartMarkup]
@run(line)
[macros]
macro initialize
writes("Output file [unite.dat]: ")
if (s:= read()) == "" then s := "unite.dat"
f := open(s,"w")
rows := 0
end
macro line
write(f,@line)
rows := rows + 1
end
macro finalize
write(rows, " lines written to ",s)
end
|
Pretty script which converts FictionBook fb2-file to html.
# fb2html.par
# Converts fb2-files to html
[startEntity]
<?xml
<FictionBook
<description>
<a@sp
<title>
<binary
<section
<subtitle
<emphasis>
</emphasis>
<strong>
</strong>
</a>
<empty-line/>
</section>
<poem>
</poem>
<stanza>
</stanza>
<v>
</v>
<strikethrough>
</strikethrough>
</FictionBook>
[stopEntity]
?>
>
</description>
>
</title>
</binary>
>
</subtitle>
@null
[startMarkup]
@run(get_encoding)
@run(bof)
<!--@start@body@stop-->
@run(get_href)
@run(title)
@run(binary_data)
<div@body>
@run(title)
<b>
</b>
<b>
</b>
</a></sup>
<p></p>
</div>
<span class="poem">
</span>
<span class="stanza">
</span>
<span class="v">
<br></span>
<del>
</del>
@run(eof)
[Options]
syncStop = true
syncMarkup = true
[Macros]
procedure initialize
encoding := "utf-8"
end
procedure get_encoding
s := @body
if (i := find("encoding=",s))>0 then {
s := ltrim(substr(s,i+9))
encoding := substr(s,2,find(s[1],s,2)-2)
}
end
procedure bof
close_output()
file := getpath(@input)||getname(@input)||".html"
open_output(file)
write_output("<html><head>\n")
write_output("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=",encoding,"\">\n")
write_output("<style>span.v { color : blue; font-style: italic; text-align: right }</style>\n")
write_output("</head>\n")
end
procedure title
s := "<h4"||@body||"</h4>"
while (i := find("<a ",s)) do {
j := find(">",s,i)
t := substr(s,i,j-i+1)
write_output(substr(s,1,i-1),"<a href=",substr(t,find("href=",t)+5))
s := substr(s,j+1)
}
write_output(s)
end
# Base64 encoded image
procedure binary_data
s := @body
if (i := find("content-type=",s))>0 then {
s := substr(s,i+14)
j := find('"',s)
t := substr(s,1,j-1)
j := find(">",s)
s := substr(s,j+1)
write_output("<image src=",@q,"data:",t,";base64,",s,@q,">")
}
end
procedure get_href
s := @body
write_output("<sup><a href=",substr(s,find("href=",s)+5),">")
end
procedure eof
write_output("</html>")
close_output()
eof()
end
|
Simple scripts which demonstrates text ordering.
# sort.par # Ordering set of lines of processed texts. # Resulting set of ordered text lines outputs to console. [startentity] @bol [startmarkup] @run(line) [macros] macro initialize p := list() end macro line put(p, @line) end macro finalize # you can use asort() instead of sort() for ordering in alpabetical order p := sort(p) while len(p) > 0 do write(get(p)) end |
This script outputs a list of tag names, which are used in source XML/SGML/HTML files.
The unique list of tag names is generated by Icon-function set(), which is used in macro-procedure finalize.
# list_tags.par
# Output list of tag names, which are used in source xml/sgml/html files.
# Commented data in <!-- ... --> ignored.
[startentity]
<
<!--
[stopentity]
>
-->
[startmarkup]
@run(tag)
@null
[Options]
syncStop=true
syncMarkup=true
[macros]
procedure initialize
p := list()
end
procedure tag
t := lower(@body)
if match("/", t) then return
if (i := upto(" \t\n",t)) > 0 then t := substr(t,1,i-1)
put(p, t)
end
procedure finalize
p := sort(set(p))
while len(p) > 0 do write(get(p))
end
|
# Name: lines-count.par # Counting of number of lines. Outputs current time and number of lines for each source file. [startentity] @eof [startmarkup] @eval(write(@date||" "||@clock,"\t", @lineno)) |
This scripts downloads file from Internet by HTTP/HTTPS protocol. You can also use for downloading the excellent utility curl, which ported to a lot of platforms (curl currently is included to Windows).
# download file by HTTP/HTTPS
[macros]
procedure initialize
f := open("https://rvb.ru/dostoevski/01text/vol1/01.htm","m-")
t := open("c:\\tmp\\01.htm","w")
while notnull(s := read(f)) do write(t,s)
close(f)
close(t)
end
|
Notes: option "m-" in open function defines connect to secure HTTPS with unauthenticated certificates allowed.
# win2unix.par
[startEntity]
@bof
@eol
@eof
[stopEntity]
[startMarkup]
@run(bof)
@run(eol)
@run(eof)
[Options]
syncMarkup = true
addNewLine = false
[Macros]
procedure initialize
# output directory
outpath := getenv("outpath")
end
procedure bof
out := open(outpath||getname(@input)||"."||getext(@input), "wu")
end
procedure eol
writes(out, @line, "\x0a")
end
procedure eof
close(out)
end
|
Below the more elegant version of EOL format converting is presented.
# Convert EOL to UNIX format
[startEntity]
@eol
[startMarkup]
@eval(write_output(@line,EOL()))
[procedures]
procedure initialize
EOL("unix")
set_option("untranslatedWrite = true")
set_option("compatibility = 4.2")
end
|
This example demonstrates how to generate SQL-script to insert data to database from source CSV. To define configuration parameters (names of columns and delimeter) the external file csv2sql.config is used. Content of this file is included with help of @include. To secure aphostor character (') within a string the function sql_quotes(s) is used. To generate list of values from csv-string the function get_csv(s,delim) is used.
# csv2sql.par
# Convert СSV data (comma separated values)
# to a set of SQL-statements insert into ... values().
# Please note, this cript maybe used for processing at time of many csv-files with the same structure.
[startEntity]
@bof
@bol
@eof
[stopEntity]
@null
@eol
@null
[startMarkup]
@run(beg_of_file)
@run(row)
@run(end_of_file)
[Options]
syncStop = true
syncMarkup = true
[Macros]
# Setup column names and value of delimiter
procedure initialize
@include csv2sql.config
end
# switch output to .sql file
procedure beg_of_file
file := getpath(@input)||getname(@input)||".sql"
close_output()
open_output(file)
cols := list()
rows := 0
end
# Generate list of column names
procedure get_column_headers
cols := get_csv(s,delim)
i := 0
every 1 to len(cols) do {
i := i + 1
if i=1 then column_headers := cols[i] else column_headers := column_headers || "," || cols[i]
}
end
# generate list of values (as char constants) from csv-string
procedure get_data_values
data := get_csv(s,delim)
i := 0
every 1 to len(data) do {
i := i + 1
val := "'"||sql_quotes(data[i])||"'"
if i=1 then values := val else values := values || "," || val
}
# add missing values as nulls
while i < len(cols) do {
i := i + 1
values := values || ",null"
}
values := values || ");"
end
# process next line of csv-file
procedure row
s := trim(@line,' \t')
if s == "" then return
rows := rows + 1
if rows = 1 then {
if column_headers == "" then {
@call get_column_headers
}
# define template of "insert" statement
sql := "insert into " || getname(@input) || "(" || column_headers || ") values ("
return
}
@call get_data_values
write_output(sql, values)
write(sql, values)
if rows % commit_cycle = 1 then write_output("\ncommit;")
end
# end of processing current csv-file
procedure end_of_file
write_output("commit;")
close_output()
end
|
Config file for this data could be defined as:
# csv2sql.config delim := ',' column_headers := "id,mgr,dept,name,salary" |
Then after processing we'll get the following SQL:
insert into personnel(id, mgr, dept, name, salary) values('7234', '7777', 'Sales', 'Tom Scott', '5700');
insert into personnel(id, mgr, dept, name, salary) values('7777', '', 'Administration', 'Alan Cruzo', '15000');
insert into personnel(id, mgr, dept, name, salary) values('7001', '1234', 'Delivery', 'Jane Fisher', '6100');
insert into personnel(id, mgr, dept, name, salary) values('1234', '7777', 'Delivery', 'John Asher', '15100');
commit;
|
Let the names of persons in source text are messed and we shall synchronically change one names to others. Ordinal search and replace is not good for that task because we shall perform many intermediate steps when text includes many messed names. With help of xMarkup this operation is simple and trivial. Let's we have "corrupted" part of Genesis (11:14):
When Eber had lived 30 years, he became the father of Shelah. And after he became the father of Shelah, Eber lived 403 years and had other daughters and sons. |
# exchange.par # Exchange names in a text [startEntity] Eber Shelah daughter son [startMarkup] Shelah Eber son daughter [Options] syncMarkup = true |
All what we had to do - define two synchronized lists of source and target values.
This is a simple example how to generate script, which shall consequentally process a list of source files by some command. Take into account using of eof() call as a parameter of write(). Function eof() returns nothing but move us to the end of file. For huge files that can dramatically speed up the process.
Note: use mode without creation of output files and supressing work messages (options "-oNUL:" and "-q" of console command).
# generate-script.par
# Generation of script to process source files
[startEntity]
@bof
[startMarkup]
@eval( write("some-command ",@input, eof()) )
|
Ready text of script may be copied from console window and written to BAT-файл.
# Transform UTF-8 to UTF-8 without BOM (byte-order-mark). # Text in UTF-8 without BOM is undistinguished from text in ANSI-encoding # if it includes only ANSI characters. # Text in UTF-8 has ahead a 3-bytes sequence (BOM) \xEF \xBB \xBF, # which is used to distingush UTF-16 big endian from UTF-16 little endian. # All transformation is to cut first 3 bytes of text. [startEntity] @bof [startMarkup] @eval(tabto(4)) |
This example demonstrates using of decoding table. Transliteration rules by www.translit.ru
# Transliteration of cyrillic file names
[startEntity]
@bof
[startMarkup]
@run(translit)
[Macros]
# define decoding table
procedure initialize
cyr := table()
cyr["А"] := "A"
cyr["Б"] := "B"
cyr["В"] := "V"
cyr["Г"] := "G"
cyr["Д"] := "D"
cyr["Е"] := "E"
cyr["Ё"] := "Jo"
cyr["Ж"] := "Zh"
cyr["З"] := "Z"
cyr["И"] := "I"
cyr["Й"] := "J"
cyr["К"] := "K"
cyr["Л"] := "L"
cyr["М"] := "M"
cyr["Н"] := "N"
cyr["О"] := "O"
cyr["П"] := "P"
cyr["Р"] := "R"
cyr["С"] := "S"
cyr["Т"] := "T"
cyr["У"] := "U"
cyr["Ф"] := "F"
cyr["Х"] := "H"
cyr["Ц"] := "C"
cyr["Ч"] := "Ch"
cyr["Ш"] := "Sh"
cyr["Щ"] := "W"
cyr["Ъ"] := "##"
cyr["Ы"] := "Y"
cyr["Ь"] := "'"
cyr["Э"] := "Je"
cyr["Ю"] := "Ju"
cyr["Я"] := "Ja"
cyr["а"] := "a"
cyr["б"] := "b"
cyr["в"] := "v"
cyr["г"] := "g"
cyr["д"] := "d"
cyr["е"] := "e"
cyr["ё"] := "jo"
cyr["ж"] := "zh"
cyr["з"] := "z"
cyr["и"] := "i"
cyr["й"] := "j"
cyr["к"] := "k"
cyr["л"] := "l"
cyr["м"] := "m"
cyr["н"] := "n"
cyr["о"] := "o"
cyr["п"] := "p"
cyr["р"] := "r"
cyr["с"] := "s"
cyr["т"] := "t"
cyr["у"] := "u"
cyr["ф"] := "f"
cyr["х"] := "h"
cyr["ц"] := "c"
cyr["ч"] := "ch"
cyr["ш"] := "sh"
cyr["щ"] := "w"
cyr["ъ"] := "#"
cyr["ы"] := "y"
cyr["ь"] := "`"
cyr["э"] := "je"
cyr["ю"] := "ju"
cyr["я"] := "ja"
end
# rename file
procedure translit
srcfile := @file
path := getpath(srcfile)
src := substr(srcfile,length(path)+1)
i := 0
trg := ""
# convert characters of input file's name with help of table cyr
while (i := i + 1) <= length(src) do {
c := src[i]
if isnull(cyr[c]) then trg := trg||c else trg := trg||cyr[c]
}
# close input file to rename it
close_input()
# now rename this file if its name is changed
if src !== trg then {
write("rename ",srcfile," ==> ",path||trg,)
rename(srcfile, path||trg)
}
end
|
This example demonstrates data processing with SQL query language. Suppose we configured ODBC data source with name mysql. Username: scott, password: tiger.
# Example of text file loading to database table
# SL, 12.12.2014
[Macros]
procedure initialize
dbsrc := "mysql"
user := "scott"
pass := "tiger"
# open connection to database
if notnull(db := open(dbsrc, "o", user, pass)) then write("Connected to: ",dbsrc) else stop("Failed to connect: ",dbsrc)
# create table in database
sql(db, "create table example(id int not null, s varchar(80))")
i := 0
# load text file example.txt to database
T := get_content("exchange.txt")
while length(T)>0 do {
s := get(T)
i := i + 1
s := substr(s,1,80)
sql(db, "insert into example(id,s) values("||i||",'"||s||"')")
}
# report count of loaded lines
sql(db,"select count(*) as cnt from example")
if notnull(row := fetch(db)) then write("loaded rows: ",row["cnt"])
# close database connection and exit
close(db)
exit(0)
end
|
# Histogram of Gaussian distribution.
[Options]
graphics = true
[Macros]
procedure initialize
SIZE := 10000
# number of categories
N := 20
# mean value
M := 0.0
# standard deviation
F := 1.0
# 97% interval M-3*F .. M+3*F
d := 6*F/N
H := table(0)
i := 0
x0 := M-3*F
while (i:=i+1)<=SIZE do {
k := integer((Gauss(M,F)-x0)/d)
if k < 1 then k := 1
if k > N then k := N
H[k] := H[k] + 1
}
Hist(H,"Histogram of Gaussian distribution")
end
|
The resulting histogram could be viewed as:
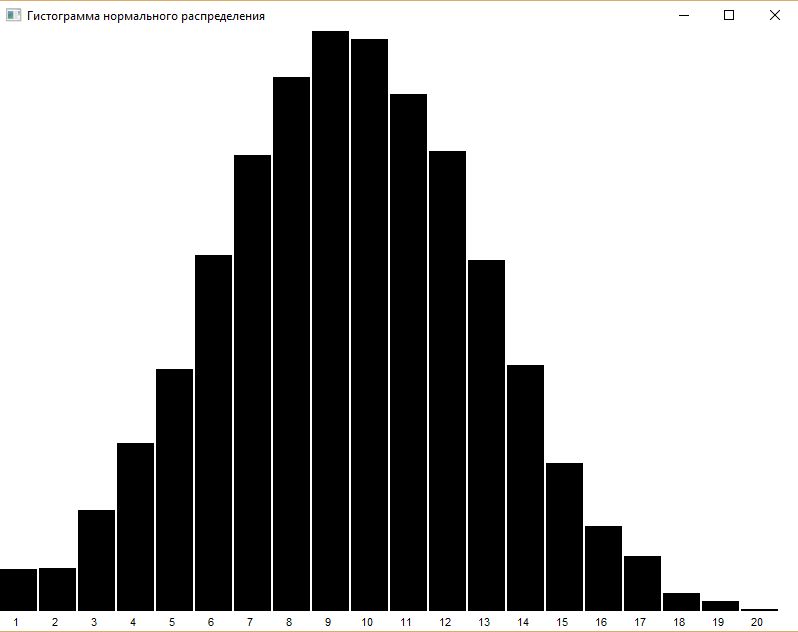
This example demonstrates how to build and visualize histogram for most frequent words in the text. Text analysis is performed with help of module wordtabulator.
# Histogram of words distribution in the text
[Options]
encoding = ANSI
graphics = true
[Macros]
procedure initialize
opts := []
put(opts,"top=10")
put(opts,"min-word-length=4")
put(opts,"sort-order=2")
put(opts,"sort-direction=1")
put(opts,"tags-process=p")
words := wt("https://rvb.ru/dostoevski/01text/vol1/01.htm",[],opts)
Hist(words, "F.M.Dostoevsky. Poor folk. 10 most frequent words.")
end
|
The resulting histogram could be viewed as:
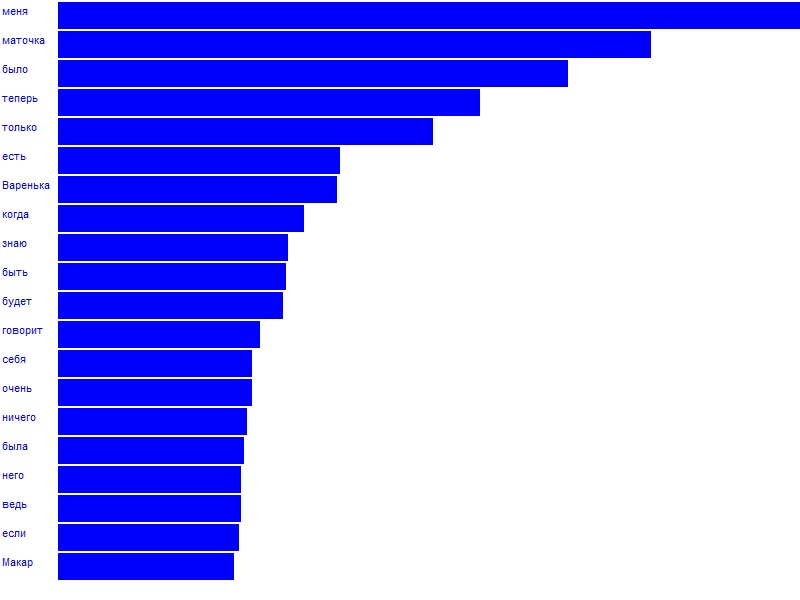
This example demostrates as visualize the most frequent words (personal names) in the text. Text analysis is performed with help of module wordtabulator.
# Most frequental personal names: F.M.Dostoevsky. "Poor folk"
[options]
graphics=true
compatibility=4.0
[procedures]
procedure initialize
opts := []
put(opts,"top=30")
put(opts,"min-word-length=3")
put(opts,"min-word-frequency=10")
put(opts,"sort-order=2")
put(opts,"sort-direction=1")
put(opts,"regular-expressions")
put(opts,"search-queries=^[А-Я]\\w+")
words := wt("https://rvb.ru/dostoevski/01text/vol1/01.htm","ignore.txt",opts)
n := length(words)
PlotWords(words,"F.M.Dostoevsky. Poor folk. "||n||" most frequent names")
end
|
The resulting diagram could be presented as:

This example demonstrates how visualize the download statistics (by countries) from site sourceforge.net. To download statistics data the utility curl is used. It's supposed that path to curl.exe is defined in environment variable PATH.
# xm_stats.par
# Visualisation of xMarkup download statistics from sourceforge.net by countries
[options]
graphics=true
[procedures]
procedure initialize
date := replace(@date,"/","-")
url := "https://sourceforge.net/projects/xmarkup/files/stats/json?start_date=2000-01-01&end_date="||date
url := @q||url||@q
write("curl "||url)
i := system("curl "||url||" --output xm.json")
if i=-1 then stop("path to curl.exe is not found in PATH variable")
s := get(get_content("xm.json"))
if (i := find("\"countries\":",s))>0 then s := ltrim(substr(s,i+12)) else stop("unknown json format")
if (i := find("]]",s))>0 then s := substr(s,1,i-1) else stop("unknown json format")
d := get_csv(s,"],")
data := []
while length(d)>0 do {
s := replace(ltrim(get(d),"["),@q,"")
L := get_csv(s,",")
write(L[1],"\t",L[2])
put(data,L)
}
# numeric parameters (20 and 200) define step and increment of radius;
# last parameter ("circle") defines vizualisation of words as circles
PlotWords(data,"xMarkup downloads from sourceforge.net by countries "||date,20,200,"circle")
end
|
The resulting diagram could be presented as:

This example presents popularity index of different programming languages, which is downloaded from site rosettacode.org.
# rosetta.par
# On the first step statistics data are downloaded from rosetta.org through MediaWiki API
# and saved to local file rosetta-data.xml
[options]
graphics=true
[procedures]
procedure readurl
write(url)
if notnull(page := open(url,"m-")) then httpread := 1 else {
httpread := 0
write("can't open: ",url)
cmd := "curl --output ./temp.html "||url
write(cmd)
if (rc := system(cmd)) != 0 then stop("can't execute: ",cmd)
page := open("temp.html","r")
}
text := ""
if httpread then if page["Status-Code"] >= 300 then stop(page["Status-Code"]," ",page["Reason-Phrase"])
if notnull(s := reads(page,-1)) then text := text || s
close(page)
end
procedure initialize
baseurl := "https://rosettacode.org/w/api.php?format=xml&action=query&generator=categorymembers&gcmtitle=Category:Programming%20Languages&gcmlimit=500&prop=categoryinfo"
f := open("rosetta-data.xml","w")
continue := ""
text := "gcmcontinue="
while (i := find("gcmcontinue=",text))>0 do {
text := substr(text,i+1)
if (i := find(@q,text))>0 then text := substr(text,i+1)
if (i := find(@q,text))>0 then {
continue := "&gcmcontinue="||substr(text,1,i-1)
text := substr(text,i+1)
}
url := baseurl||continue
@call readurl
writes(f,text)
}
close(f)
load_script("rosetta-viz.par")
execute_processing(["rosetta-data.xml"])
end
|
# rosetta-viz.par
# On the second step data from file rosetta-data.xml is vizualised.
[startentity]
<page@sp
[stopentity]
</page>
[startmarkup]
@run(page)
[procedures]
procedure initialize
data := table(0)
end
procedure page
s := @body
lang := ""
rank := 0
while (i := find("<page ",s))>0 do s := substr(s,i+1)
if (i := find("Category:",s))>0 then {
s := substr(s,i+9)
if (i:= find(@q,s))>0 then lang := substr(s,1,i-1)
if (i := find("pages=",s))>0 then {
s := substr(s,i+7)
if (i:= find(@q,s))>0 then rank := integer(substr(s,1,i-1))
}
if lang !== "" then if rank >0 then data[lang] := rank
}
end
procedure finalize
data := reverse(sort(data,2))
rank := 0
write()
write("rank\tLanguage\tentries")
write("====\t========\t=======")
while (rank:=rank+1) <= length(data) do {d := data[rank]; write(rank, "\t", d[1],"\t",d[2])}
PlotWords(data,"Rosetta Code/Rank languages by popularity "||@date)
end
|
Resulting diagram could be presented as following (Unicon at 45th place, and Icon on 53th):

There is given the script, which implements simple GUI with help of Unicon. Thsi is a tiny application to browse image files in selected parent directory and all included ones. Navigation by images (previous-next) is produced with help of arrow keys. Quit - by pressing "q" or Esc.
The principles of graphics in Icon/Unicon are very well descibed in the classic book Graphics Programming in Icon.
# Tiny script which demonstrates graphics features of Unicon.
# Alert: some images may be dispiayed incorrect!
# (C) SL, 2022-04-05
[options]
graphics = true
compatibility = 4.6
procedure initialize
w := WOpen("label=Browse images", "font=Times New Roman,14", "size=400,300")
s := TextDialog("Select folder", [], [], [], ["Go!"])
if isnull(s) then exit(0)
if isnull(file := WinOpenDialog("Select first image", "", 30, "All images|*.png;*.jpg;*.bmp;*.gif|")) then exit(0)
d := getpath(file)
L := listfiles(d||"*.(png|jpg|bmp|gif)",1)
i := 0
j := 1
while (i:=i+1)<=length(L) do if file == L[i] then {j := i; i := length(L)+1}
WAttrib("size=1920,1080")
while 1 do {
file := L[j]
EraseArea()
ReadImage(file)
WAttrib("label="||file)
i := j
e := Event()
if e in ["q","\e"] then exit()
if integer(e) in [39,40] then j := j + 1
if integer(e) in [37,38] then j := j - 1
if i = j then Alert()
if j > length(L) then {j := j-1; Alert()} else if j < 1 then {j := 1; Alert()}
}
end
|
An example of script's graphic window:

This example demonstrates frequency analysis of data in database field. Let's use for that an hyphotetic phone dictionary with lastnames of abonents. Find 30 most frequent lastnames and visualize them.
# db-analyze.par
# Analysis and visualization of data in database table
# SL, 2020-10-20
[options]
graphics = true
compatibility = 4.6
[procedures]
procedure initialize
# conenct to ODBC data source
if isnull(db := open("dbf","o","user","pass")) then stop("Connect error to data source!")
write("Reading data ...")
L := list()
T := table()
# read data from column lname of table phone
sql(db,"select lname from phone")
# Construct resulting table T (value, frequency)
while notnull(row := fetch(db)) do {
s := row[1]
if notnull(n := T[s]) then T[s] := n + 1 else T[s] := 1
}
close(db)
# sort table of results by frequency
T := sort(T,2)
n := length(T)
i := 0
j := n
# get 30 most frequent values (i.e. last ones)
while (i < 30) do {
t := T[j]
put(L, t)
i := i + 1
j := j - 1
write(right(i,2," ")," ",t[1]," ",t[2])
}
PlotWords(L,"Database analysis","radius=200 delta=200 theme=text")
end
|
Results of database analysis:

Data processing may be highly speeded up, if convert xMarkup script to binary executable file. In this case maybe guaranteed performance boost in 10-20 and more times. Binary file of script can be created in GUI or manually with help of utility xm2exe, which located in bin folder of xMarkup home.
Let's for example convert script examples/anlayse_tags.par to binary file.
xm2exe -p..\examples\analyse_tags.par analyse_tags.par.exe -f..\docs\*.htm -p..\examples\analyse_tags.parAlert. You should make some pre-configuration to proper working of xm2exe utility:
ipl to local disk.make.bat located at folder xmwin/bin of xMarkup installation:ipl/gprocs and ipl/procs in IPATH variable.xmwin/src of xMarkup installation.xmwin/bin to PATH variable.Using utility xm2exe absolutely identical both for MS Windows and POSIX\UNIX systems.
xMarkup utility may use Icon or Unicon Programming Language as a programming environment. Unicon is an object-oriented extension and next generation of Icon, with which it's completly compatible. It should be noted however what for Linux systems Unicon has slightly less performance than Icon.
As Icon (Unicon) is a cross-platform language xMarkup utility may be used on any system, which supports Icon (Unicon). Now Icon is available for the following UNIX systems:
To build binary file of xMarkup on required system you shall install Icon (Unicon) compiler and then make utility from the source code. The Icon distributives for different OS and source code are availaible for download from Icon Project Home http://www.cs.arizona.edu/icon/. Unicon compiler for each supported platform has to be maked from the sources, which available at SVN repositary. The sources of xMarkup are available at SourceForge.net.
gunzip <linux-x86-vXXX.tgz | tar xf –This step is requried when prebuilded binaries of Icon are not compatible with your specific system.
gunzip <icon-vXXXsrc.tgz | tar xf –make Configure to output available configurations.make Configure name=xxx to choose required configuration xxx.make to build Icon binaries.gunzip <xm-source-X.Y.tgz | tar xf -icont and iconx to directory xmarkup/binenv.icn# check existance of following lines:$define UNIX 1$define ICON 1# comment or remove following line if it exists:$define UNICON 1
make and define mode=ICONsh make to build xMarkup binaries.xm in directory xmarkup/binAs there isn't official Unicon binaries for Linux/Mac systems you have only option to build Unicon from the sources for these systems.
unzip unicon-code-XXXX-trunk.zipmake Configure to output available configurations.make Configure name=xxx to choose required configuration xxx.make Unicon to build Unicon binaries.icont, iconx and unicon in directory unicon/bingunzip <xm-source-X.Y.tgz | tar xf -icont, iconx and unicon to directory xmarkup/binenv.icn# check existance of following lines:$define UNIX 1$define UNICON 1# comment or remove following line if it exists:$define ICON 1
make and define mode=UNICONsh make to build xMarkup binaries.xm in directory xmarkup/bin|
|
|