Утилита xMarkup предназначена для выполнения процедур строковых преобразований в множестве текстовых файлов. Эти процедуры могут быть сколь угодно сложными и изощренными в отличие от обычных процедур поиска и замены текста. Фактически, в утилите реализован процедурный язык, на котором можно описать любые алгоритмы преобразования данных. Однако, в большинстве случаев использование процедурных расширений является излишним. Пользователю достаточно только определить маркеры начала и конца искомых элементов текста и задать шаблоны их преобразования.
Данная утилита может успешно использоваться для генерации, редактирования или удаления любых текстовых элементов в исходных файлах. Утилита первоначально разрабатывалась как любительская программа, однако сейчас служит для вполне серьезных вещей - с ее помощью на сайте Русской Виртуальной Библиотеки готовятся все публикуемые тексты. Перечислим очевидные варианты использования утилиты:
В качестве экзотических вариантов использования можно было бы назвать выполнение математических вычислений или проверку программного кода.
Утилита реализована в виде консольного приложения для MS Windows и написана на языке Icon. В последствии был осуществлен переход на язык программирования Unicon, являющийся болеее мощным вариантом развития языка Icon. Так как Icon (Unicon) является кросс-платформенным языком, то утилита может быть портирована для других операционных систем, отличных от MS Windows. В главе 9 описывается сборка утилиты для других платформ, в частности POSIX\UNIX-подобных систем.
Запуск утилиты осуществляется с помощью командной строки:
xm -p file [-f list] [-o path] [ключи]
|
Описание опций:
-p file |
Путь к файлу скрипта обработки. |
-f list |
Список файловых путей через точку с запятой (;), определяющий набор обрабатываемых файлов. Путь со знаком минус (-) впереди задает его исключение из обработки. Например:-f*.htm;*.txt;-index.htm;-index.txtВместо самого списка можно указать файл, содержащий этот список: -f @file. |
-o path |
Путь записи результатов (по умолчанию, NUL:). Для вывода результатов на консоль можно указать CON:. |
Ключи:
-c |
Задает автоматическое создание папки записи результатов, если ее не существует. |
-r |
Задает рекурсивный поиск файлов в поддиректориях. |
-s |
Задает предварительную сортировку обрабатываемого списка файлов. |
-q L |
Задает уровень L вывода статистики обработки: 0 - печать полной статистики (по умолчанию); 1 - подавляет вывод статистики; 2 - печать только списка обрабатываемых файлов; 3 - печать только заключительнйо статистики (затраченное время и количество обработанных файлов). |
-debug |
Задает интерактивный режим отладки. |
-help |
Выводит данный экран помощи. |
-version |
Печатает информации о текущей версии утилиты. |
Если при запуске утилиты по какой-либо причине возникает следующая ошибка:
| error in startup code |
| xm.exe: cannot open interpreter file |
то вам необходимо добавить путь к исполнимому файлу утилиты в переменную среды PATH:
| C:\> set path="c:\Program Files\xmwin\bin";%path% |
Версия 1.0.1, август 1999
Создана первая экспериментальная версия утилиты, которая затем неоднократно переписывалась и улучшалась. Фактически, процесс превращения гадкого утенка в устойчиво работающую программу был завершен только летом 2001 года.
Версия 1.6.3, август 2001
1. Утилита стала максимально расширяемой в смысле возможностей, так как появились процедурные макросы на Icon-диалекте. Т.е. теперь стало возможным писать свои процедуры разметки, в которых доступны вызовы ВСЕХ (!) встроенных функций языка Icon версии 9.3.2.
2. Улучшена работа со счетчиками, число которых теперь теоретически не ограничено! Добавлены специальные макроопределения, позволяющие генерировать значения счетчиков и сбрасывать их в начальное значение. Для совместимости с предыдущими версиями маркапа оставлена возможность автоматической инкрементации счетчиков (параметр autoIncr). Исключено за ненадобностью макроопределение подчиненного счетчика @@counter.
3. Добавлены новые макроопределения проверки позиции в пределах исходного файла (начало или конец файла). В связи с этим из файла параметров исключена секция [Embed], которая позволяла раньше добавлять нужный текст внутрь заголовка html-документа.
4. Введены макроопределения @bol, @eol проверки позиции в пределах строки (начало или конец).
5. Введены новые макроопределения, задающие наборы различных символов и системные переменные, например, текущее время.
6. Добавлено макроопределение @eval, с помощью которого можно вычислить значение выражения "на лету", например, @eval(len(@line)) вернет длину текущей строки.
Версия 1.6.8, февраль 2002
1. Исправлены некоторые мелкие и досадные ошибки.
2. Задание множества обрабатываемых файлов в командной строке списком (@file).
3. Добавлена функция likeword(s), с помощью которой можно проверить, похожа ли подстрока s на слово в составе обрабатываемой строки текста.
4. Добавлены служебные макроопределения @subject (остаток исходной строки, начиная с позиции за стоповым маркером) и @pos (позиция сдвига в @subject).
Версия 1.6.9, июль 2002
Исправлены замеченнные ошибки.
Версия 1.7.0, сентябрь 2004
1. Добавлена функция tabto(i), осуществляющая сдвиг к i-ой позиции подстроки @subject. Позиция сдвига задается макроопределением @pos. Вызов tabto(0) осуществляет сдвиг к концу текущей строки и следовательно задает переход к обработке следующей строки текста.
2. Добавлена функция like(s1,s2) проверяющая строку s1 по поисковой маске s2. Функция возвращает 1 (true), если s1 соответствует маске s2, иначе прерывание &fail.
3. Добавлен отладочный режим, задаваемый параметром debug=true в секции [options].
Версия 1.7.1, февраль 2005
1. Исправлены ошибки при обработке специальных символов (\c) в составе строковых констант.
2. Добавлена операция проверки на неравенство для строковых выражений ( a !== b ).
3. Доработан вывод в режиме отладки.
4. Добавлены ключи "-h" и "-d" в командной строке запуска утилиты.
5. Добавлено макроопределение @nfiles числа обрабатываемых файлов.
6. Переработаны примеры в руководстве в целях их более легкого восприятия.
Версия 1.7.2, март 2005
1. Исправлены ошибки при обработке некоторых макро-определений, заданных в качестве значений стартовых/стоповых маркеров.
Версия 1.7.3, ноябрь 2005
1. Исправлена ошибка при обработке строк, оканчивающихся последовательностью символов обратной косой черты (\).
Версия 1.8.0, сентябрь 2006
1. Добавлены две предопределенные макро-процедуры "initialize" и "finalize", которые автоматически выполняются соответственно в начале и в конце процесса обработки. Данные процедуры при необходимости могут быть заданы в секции [macros].
2. Исправлена ошибка, связанная с обработкой последовательности стартовых маркеров @bof, @bol. В прежних версиях утилиты при обработке такой последовательности маркеров пропускалась первая строка текста.
3. Немного ускорен процесс поиска стартовых/стоповых маркеров.
Версия 2.0, апрель 2007
1. Создан графический интерфейс утилиты.
2. Исправлена ошибка обработки составной многострочной конструкции в фигурных скобках {}, когда закрывающая скобка в отдельной строке вызывала ошибку.
3. Добавлена опция командной строки -c для создания иерархической папки результатов, копирующей иерархию папок исходных файлов.
4. Добавлена опция командной строки -q1 для нужд графического интерфейса.
5. Добавлено макроопределение @regexp() для задания регулярного выражения в качестве стартового/стопового маркера.
6. Доработана функция substr(), которая теперь возвращает пустое значение вместо &fail прерывания, если невозможно выделить заданную подстроку из исходной строки.
7. Исправлена ошибка описания макроопределений @subject и @pos.
8. В состав значений макроопределений @cp866, @cp1251 и @cletters добавлены буквы ё и Ё, ранее пропущенные.
Версия 2.0.1, июль 2007
1. Исправлена ошибка в значении @subject (раньше отсекался последний символ строки).
2. Исключена операция сохранения файла параметров при включенной опции автосохранения, если он на самом деле не изменялся.
Версия 2.1.0, октябрь 2007
1. Добавлена опция -x отладочной проверки макро-процедур в режиме эмуляции их выполнения.
2. Добавлена директива @include, с помощью которой задается включение текста в файл параметров из внешнего файла.
3. Добавлены макро-определения @version, @features, @host, @input, @output, @errout, @e и @pi.
4. Добавлена функция sql_quotes(s), заменяющая одиночный символ апострофа (') на двойной ('') внутри строки s.
5. Доработан графический интерфейс утилиты - добавлена возможность задания оформления консольных и рабочих окон.
6. Создана версия утилиты для POSIX/UNIX-подобных операционных систем.
Версия 2.1.1, апрель 2008
1. Добавлены новые возможности:
-oCON: весь вывод перенаправляется на экран и выходные файлы не создаются. Этот режим вывода добавлен в графический интерфейс.@include в окне процедурных макросов открывает включенный файл на редактирование.2. Исправлен ряд мелких шероховатостей и ошибок. В том числе зафиксирована ситуация, когда не записываются результирующие файлы в режиме вывода в иерархическую папку.
3. Исключена ситуация когда выходные файлы могут переписать входные файлы, если пользователь преднамеренно указал входные и выходные пути одинаковыми.
Версия 2.1.2, май 2008
1. Добавлено макроопределение @call для "вызова" из тела макро-процедуры другой макро-процедуры.
2. Исправлена досадная ошибка версии 2.1.1, связанная с неправильным определением пути при чтении/записи файлов, если путь был явно не указан.
Версия 2.1.3, сентябрь 2008
1. Добавлены новые функции:
eof() быстрого перехода в конец исходного файла, чтобы пропустить его обработку;file_exists(s) проверки существование указанного файла s;get_separator() возвращающая символ-разделитель, используемый в пути файла: (/) для Unix или (\) для Windows;sortfiles(L) сортировки списка имен файлов согласно иерархии путей в их именах.2. Добавлена опция -s, которая задает предварительную сортировку списка обрабатываемых файлов согласно иерархии путей.
3. Отменен режим создания выходных файлов по умолчанию; для создания выходных файлов требуется явно задать путь в опции -o.
4. С сайта https://sourceforge.net/projects/xmarkup/ можно скачать исходный код утилиты, чтобы сделать сборку под необходимую UNIX-платформу (см. главу 9).
Версия 2.1.4, январь 2009
1. Исправлена ошибка в макросе @time, который должен возвращать текущее время выполнения программы.
2. Исправлена ошибка графического интерфейса - в предыдущей версии не работал режим сохранения выходных файлов с добавлением префикса "xm$" к имени исходного файла.
3. На закладке "Помощь" графического интерфейса добавлена ссылка к домашней страничке загрузки программы.
Версия 2.1.5, апрель 2010
1. Добавлены новые функции:
read_input(i) упреждающего чтения строк обрабатываемого файла;tabto(i) упреждающего чтения символов в обрабатываемой строке;asort(L) алфавитной сортировки списка строк;unicode(i) преобразования десятичного NCR Unicode для кириллицы в символ Windows-1251;diacritic(i) преобразование десятичного кода диактритичного символа ISO-8859-1 в именованный HTML-символ;greek(i) преобразование десятичного Unicode NCR для греческого в именованный HTML-символ;utf2ncr(s)преобразование строки UTF-8 в строку символов Unicode NCR (&#DDDD;).2. Добавлен оператор сравнения "in" в логических выражениях предложения "if". Например, выражение x in ["a","b",1,2] вернет 1, если значение x равно "a","b",1 или 2, и 0 в противном случае.
3. Состав множества буквенных символов в регулярном выражении \w дополнен буквами кириллицы.
4. Исправлены незначительные шероховатости графического интерфейса.
5. Добавлена функциональность автоматической проверки обновлений программы.
Версия 2.1.6, август 2010
1. Добавлены новые функции:
isnull(x) проверки того, что выражение x возвращает fail-прерывание или не имеет никакого значения;notnull(x) проверки того, что выражение x возвращает какое-нибудь значение;get_csv(s,delim) получения списка значений-через-разделитель (CSV) из строки s;ltrim(s,c) удаления из начала строки s символов, заданных множеством c.2. Исправлены ошибки в следующих функциях:
listfiles(s,i) для длинных путей, содержащих в своем составе пробелы;getname(s) для случаев, когда в имени файла содержится одна или более точек (.);getext(s) для случаев, когда имя файла имеет пустое расширение;close_output(), ранее значение @output после выполнения функции не очищалось.3. Изменен графический интерфейс утилиты:
Версия 2.1.7, январь 2011
1. Добавлены новые функции:
lfind(L,x) поиска элемента списка L, имеющего значение x;close_input() закрытия и прекращения обработки текущего исходного файла.2. Исправлена ошибка, связанная с некорректным отображением кириллических имен файлов в окне результатов обработки.
3. Синхронизирован порядок символов в макро-определениях @cp1251 и @cp866.
Версия 2.1.8, декабрь 2011
1. Исправлена ошибка при обработке в режиме пропуска тела HTML-тегов (опция skipTags).
2. Оптимизирован процесс поиска, в результате чего значительно повысилась производительность. Особенно это можно заметить при обработке файлов с очень длинными строками (в этом случае гарантировано увеличение производительности в 10^N, где N>2).
3. Добавлены и слегка переработаны примеры.
Версия 3.0, май 2012
1. Переработан и оптимизирован консольный модуль утилиты. В случае обработки файлов с экстра-длинными строками гарантирован дополнительный прирост производительности.
2. Добавлена поддержка скриптов в кодировке UTF-8. Хотя GUI пока не может правильно отображать символы UTF-8, обработка выполняется правильно.
3. Удалена устаревшая опция "tagExceptions", с помощью которой задавался список парных тегов, контент которых следует пропустить при обработке. Это может быть сделано стандартными средствами с помощью стартовых и стоповых маркеров.
4. Добавлены новые функции:
get_length(s) вычисления длины строки в символах (а не байтах); строка может содержать NCR и именованные HTML-символы;hex2int(s) преобразования 16-ричного кода в целое, например hex2int("ff") вернет 255;utf2str(s) преобразования строки в UTF-8 в ANSI-строку (непреобразуемые символы кодируются как Unicode NCR и HTML именованные символы);str2utf(s) преобразования строки ANSI-символов в UTF-8;ncr2char(i) преобразования десятичного кода Unicode NCR в ANSI-символ; эта функция заменила прежнюю функцию unicode(i).ncr2utf(i) преобразования десятичного кода Unicode NCR в символ UTF-8;5. Добавлены две вспомогательные консольные утилиты:
xm2exe.exe преобразования исходного скрипта xMarkup в двоичный исполнимый файл;xmcomp.exe отладочной компиляции скрипта xMarkup с помощью компилятора Icon.Версия 3.2, ноябрь 2012
В октябре планировался выпуск версии 3.1, которая так и не вышла, а была доработана до версии 3.2.
1. Исправлена ошибка, из-за которой в версии 3.0 "случайно" отключился режим отладки.
2. Исправлена ошибка отсутствия значения макроопределения @body, когда стартовый и стоповый маркер задают начало @bol и конец строки @eol.
3. Добавлен режим обработки данных в кодировке UTF-8 (опция -u). Для этого режима были адаптированы регулярные выражения и поиск без учета регистра.
4. Исправлена ошибка в функции utf2ncr(s).
5. Добавлены новые функции:
utf8_upper(s) преобразования строки UTF-8 в "верхний регистр" (заглавные буквы);utf8_lower(s) преобразования строки UTF-8 в "нижний регистр" (прописные буквы).6. Графический интерфейс портирован из Delphi 7 в открытую среду разработки Lazarus IDE.
Версия 3.3, январь 2014
1. Исправлена ошибка в функции utf_upper(s).
2. Добавлены новые функции:
dir_exists(s) проверки существования и доступности на запись указанной папки;make_dir(s) создания указанной папки, если она не существует;set_output(s) перенаправления записи результатов в указанную папку;set_encoding(s) задания кодировки (ANSI/UTF-8) обрабатываемых файлов;add_input(s) добавления файла в список обрабатываемых файлов;open_input(s) открытия указанного файла в качестве текущего обрабатываемого;load_script(s) загрузки указанного скрипта обработки в качестве текущего;execute_processing(L) запуска процесса обработки указанного списка файлов текущим скриптом.3. Добавлено макроопределние @script, возвращающее спецификацию текущего скрипта обработки.
4. Реализован простой механизм пошаговой обработки данных.
Версия 3.4, июль 2014
Осуществлен переход на язык программирования Unicon вместо Icon. Данный шаг был вызван тем обстоятельством, что Unicon является расширением Icon и в отличие от последнего динамично развивается и поддерживается для Windows ОС. Немногочисленные обновления Icon выходят исключительно для POSIX/UNIX подобных систем (в том числе и для Cygwin). Используемая xMarkup версия Icon для MS Windows была выпущена еще в 1997 году и поэтому сильно устарела. Так как исходный код Icon на 100% совместим с Unicon "переезд" не потребовал никаких изменений. Более того, использование Unicon для Windows обеспечивает прирост производительности в среднем на 30% (для Windows7/8 и современного "железа" до 40-45%). При этом Unicon значительно расширяет возможности xMarkup, а именно:
Следует оговориться, что использование всех этих возможностей в полной мере потребует некоторой доработки утилиты. Это произойдет только в следующих выпусках.
Версия 3.5, февраль 2015
-i вывода списка свойств, поддерживаемых текущей реализацией ядра утилиты.replace(s,s0,s1) замены в строке s всех появлений подстроки s0 на s1.listfiles(s,i), возвращающая список файлов по заданной маске s. Язык Unicon в отличие от Icon реализует кросс-платформенные средства работы с файловой системой и директориями, поэтому эта функция была переписана заново.Версия 3.6, июнь 2015
-x командной строки утилиты.replace_first(s,s0,s1) замены в строке s только первой подстроки s0 на s1.rand(x) генерации псевдослучайного значения в диапазоне (1,x).oldcyr2rus(s,l) трансляции кириллического текста UTF-8 в дореформенной орфографии к современному стилю.xm2exe.Версия 4.0, август 2016
graphics, encoding, untranslatedRead, untranslatedWrite.Hist визуализации гистограмм.PlotWords.wt, реализующая интерфейс с модулем wordtabulator анализа текстов.Gauss генерации псевдослучайного значения нормального распределения.set_option задания необходимой опции обработки, смотри п.4.4.initialize.xm2exe и xmcomp.Версия 4.1, январь 2017
compatibility, с помощью которой указывается минимальный номер версии совместимости скрипта.Версия 4.2, июнь 2017
Версия 4.5, Сентябрь 2020
set_input(s), set_output(s),
html2txt(s), roman(i),
unroman(s).Версия 4.6, Апрель 2022
Версия 4.7, Май 2023
ExtractDate выделения из исходной строки даты в заданном формате.str2date преобразования строки в дату по заданному формату.date2str преобразования даты в строку по заданному формату.IsLeapYear проверки, что указанный год является високосным.julian вычисления порядкового номера Юлианского дня (IPL datefns.icn).unjulian вычисления даты по значению Юлианского дня (IPL datefns.icn).dateGt сравнения двух дат на больше.dateLt сравнения двух дат на меньше.dateEq сравнения двух дат на равенство.dateBetween проверки даты на принадлежность интервалу.gregor2julian преобразования даты по Грегорианскому кадендарю (н.ст.) в дату по Юлианскому (ст.ст.).julian2gregor преобразования даты по Юлианскому кадендарю (ст.ст.) в дату по Грегорианскому (н.ст.).date_output печати даты, которая представлена записью date_rec.Replace замены подстроки в строке по заданному регулярному выражению.Файл правил обработки (скрипт обработки) включает несколько секций, в которых определяются поисковые условия и шаблоны преобразования элементов текста, а также дополнительные параметры обработки. Каждая секция начинается со стандартного заголовка в квадратных скобках []. Имена секций нечувствительны к регистру символов. Состав и порядок секций в файле произвольный. В вырожденном случае файл может включать одну единственную секцию [macros] или [procedures], или вообще единственную процедуру main(). В последнем случае файл скрипта будет неотличим от исходного файла программы Icon/Unicon.
В файле правил обработки можно задавать комментарии в виде строк, начинающихся символом решетки (#) или точки с запятой(;), и вставлять для читабельности пустые строки, которые игнорируются при обработке. Строки комментариев в начале файла формируют блок заголовка.
С помощью стартовых маркеров задаются шаблоны поиска начала текстовых элементов, которые должны быть преобразованы. Стартовый маркер может определяться символьной строкой, множеством символов или позицией в текущем файле или строке. Для задания стартовых маркеров могут использоваться макроопределения.
Список стартовых маркеров задается в секции [startEntity], например:
[startEntity] ; поиск элементов, начинающихся цифрой @digits ; поиск HTML-тега title <title> ; поиск элементов, начинающихся двумя пробелами @space@space |
С помощью стоповых маркеров определяются шаблоны окончаний текстовых элементов, которые должны быть преобразованы. Стоповый маркер может определяться символьной строкой, множеством символов или позицией в текущем файле или строке. Для задания стоповых маркеров могут использоваться макроопределения.
Список стоповых маркеров задается в секции [stopEntity], например:
[stopEntity] @sp </title> @null |
С помощью шаблонов замен задаются процедуры преобразований искомых текстовых элементов. Шаблон замен представляет из себя строку, значение которой подставляется вместо найденного элемента текста (т.е. текста, начинающегося стартовым маркером и заканчивающегося стоповым маркером). В состав шаблона могут включаться как статические элементы, так и динамические, заданные соответствующими макроопределениями.
Список шаблонов замен задается в секции [startMarkup], например:
[startMarkup] @start<font color="red">@body</font>@stop @null @space |
Если в каждом случае преобразования требуется выполнить заключительную однотипную подстановку, то она может быть задана в необязательной секции [stopMarkup].
Дополнительные параметры определяют режимы работы и переменные утилиты. Параметры задаются в необязательной секции [Options]:
| Параметр | Описание |
minBodyLen = i |
минимальная длина текста между стартовым и стоповым маркерами (по умолчанию 0); |
counterInit = i0,i1,... |
список начальных значений счетчиков (по умолчанию 1); |
counterIncr = i0,i1,... |
список значений приращений счетчиков (по умолчанию 1); |
counterType = {REL|ABS} |
тип счетчиков: REL задает сброс всех счетчиков в начальное значение при открытии очередного обрабатываемого файла; |
autoIncr = {true|false} |
если true, значение счетчика автоматически инкрементируется при каждом вызове макроопределения @counter(); |
ignoreCase = {true|false} |
если true, задается нечувствительный к регистру поиск стартовых и стоповых маркеров; |
skipTags = {true|false} |
если true, при обработке пропускается тело всякого HTML-тега; |
syncStop = {true|false} |
если true, списки стартовых и стоповых маркеров обрабатываются синхронно; |
syncMarkup = {true|false} |
если true, списки стартовых маркеров и шаблонов замен обрабатываются синхронно; |
addNewLine = {true|false} |
если true, в конец каждой строки исходного файла добавляется символ перевода строки. |
debug = {true|false} |
задается режим отладки, позволяющий пошагово проследить процесс обработки текста. |
untranslatedRead = {true|false} |
задает режим чтения в формате нетранслируемого байтового потока (в отличие от построчного чтения). |
untranslatedWrite = {true|false} |
задает режим записи в формате нетранслируемого байтового потока (в отличие от построчной записи); в этом режиме автоматически отключается добавление символов конца строки (addNewLine=false). |
encoding = {ANSI|UTF8} |
задает формат кодирования обрабатываемых файлов. |
graphics = {true|false} |
задает режим вывода графики в отдельном графическом окне. |
compatibility = x.y.z |
задает номер версии совместимости: при запуске такого скрипта утилитой, версией младше указанной, выводится сообщение об ошибке. |
Имена параметров нечувствительны к регистру. Любой из перечисленных параметров может быть задан из тела макро-процедуры с помощью функции set_option.
Если требуется пропустить при обработке разметочные теги, то следует использовать опцию skipTags=true.
Процедурные макросы задаются в необязательной секции [Macros] или [Procedures]. Использование макросов оправдано в тех случаях, когда требуется произвести нестандартную обработку исходного текста, а не просто "поиск-замену".
Каждая макро-процедура начинается заголовком
| macro имя |
или
| procedure имя |
и заканчивается строкой
| end |
Для согласования с правилами Icon для именования макросов рекомендуется использовать только латинские буквы, цифры и символ подчеркивания (причем имя не должно начинаться цифрой).
Тело макроса состоит из набора предложений макро-языка, описанного в секции 5. Макрос работает как процедура и может возвращать значение, например:
[Macros] macro increment ; если текущая строка начинается числом n, то возращает значение n+1 if i := many(@digits, @line)-1 then return numeric(substr(@line,1,i)) + 1 end |
Макро-процедуры вызываются на выполнение из строки шаблона замен с помощью макроопределения @run(), например
[startmarkup] @start@run(name)@stop |
Все имена функций и переменных внутри макроса являются чувствительными к регистру! Для согласования с правилами Icon для именования переменных рекомендуется использовать только латинские буквы, цифры и символ подчеркивания (причем имя не должно начинаться цифрой).
Типы переменных как и в Icon явно не специфированы, а определяются текущими значениями. Наряду с пользовательскими переменными можно использовать макроопределения утилиты (в режиме read-only) и переменные счетчиков (counter, counterIncr, counterInit). Значения последних задаются как элементы массива и их можно перевычислять, например:
counter[1] := counterInit[1] counter[1] := counter[1] + counterIncr[1] |
Начиная с версии 1.8.0 введены две предопределенные макро-процедуры "initialize" и "finalize", которые автоматически выполняются соответственно в начале и в конце процесса обработки списка исходных файлов. С помошью процедуры "initialize" можно инициализировать необходимые переменные, используемых в процессе обработки. С помошью процедуры "finalize" можно выполнить необходимые действия после завершения процесса обработки. Данные процедуры необязательные и могут быть опущены.
[macros]
procedure initialize
write("Начало обработки...")
total := 0
end
procedure finalize
write("Конец обработки.")
write("total: ",total)
end
|
Язык, используемый для задания процедурных макросов, является упрощенным диалектом языка Icon и поддерживает следующие возможности:
- арифметика целых и вещественных чисел;
- обработка строковых значений;
- переменные, макроопределения и массивы;
- вызовы любых встроенных функций Icon;
- унарные операторы:
+ (абсолютное значение)
- (отрицание);
- оператор присваивания:
:=
- бинарные арифметические операторы:
+ (сложение)
- (вычитание)
* (умножение)
/ (деление)
% (вычисление остатка от деления)
^ (возведение в степень)
- оператор конкатенации строк:
||
- логические операторы сравнения для числовых выражений (возвращают 1 при истинности условия
или 0 в противном случае):
= (равенство)
!= (неравенство)
< (меньше)
<= (меньше или равно)
> (больше)
>= (больше или равно)
- логические операторы сравнения для строковых выражений (возвращают 1 при истинности условия
или 0 в противном случае):
== (равенство)
!== (неравенство)
- логический оператор проверки наличия значения x в X, где x - любая переменная или константа, а Х - таблица, множество или список:
x in X
- блоки предложений в фигурных скобках:
{}
- предложения проверки условий:
if-then
if-then-else
- предложения цикла:
while-do
every-do
- строки комментариев, начинающиеся с символа "#" или ";".
Перечисленные возможности были реализованы с помощью программы icalc.icn, разработанной Стивеном Вэмплером (Stephen B. Wampler). Данная программа входит в состав публичной библиотеки программ Icon и предназначена для моделирования работы инфиксного калькулятора. Блестящие идеи, заложенные в этой программе, позволили раширить и доработать ее до уровня интерпретатора Icon-процедур. В какой-то момент пришла мысль использовать этот интерпретатор для xMarkup. Результаты оказались весьма плодотворными.
Для желающих ознакомиться со всеми возможностями языка Icon ныне доступна электронная версия замечательной книги многоуважаемого Ральфа Грисволда The Icon Programming Language.
На сайте unicon.org/ubooks.html представлена библиотека с бесплатными книгами в формате PDF, посвященными языку Unicon.
Прекрасное руководство Unicon Programming по языку Unicon подготовил участник проекта Brian Tiffin.
Предложение ::= Выражение | If | Цикл | Оператор-возврата | Блок-предложений
Блок-предложений ::= {Список-предложений}
Список-предложений ::= Предложение | Предложение ; Список-предложений
If ::= if Выражение then Предложение Else
Else ::= else Предложение | ""
Цикл ::= While-цикл | Every-цикл
While-цикл ::= while Выражение do Предложение
Every-цикл ::= every Выражение to Выражение do Предложение
Оператор-возврата ::= return { Выражение | "" }
Выражение ::= Условие | Переменная := Выражение
Условие ::= Терм {= | != | < | > | >= | <= | == | !== | in } Терм | Терм
Терм ::= T { + | - } Терм | T
T ::= F { * | / | % } T | F
F ::= E ^ F | E
E ::= L | { + | - | || } L
L ::= Функция | Переменная | Константа | ( Выражение ) | Строка | Множество-символов | Макроопределение | Список
Функция ::= Идентификатор ( Список-аргументов )
Переменная ::= Идентификатор | Идентификатор[ Выражение ]
Константа ::= число (целое или вещественное)
Строка ::= "строка в двойных кавычках"
Множество-символов ::= 'строка в апострофах'
Макроопределение ::= &Идентификатор | @Идентификатор
Список ::= [ Список-аргументов ]
Список-аргументов ::= "" | Выражение | Выражение , Список-аргументов
|
Каждое предложение макро-языка записывается в отдельной строке и не может быть продолжено на следующих строках. Исключение составляет блок предложений, заключенный в фигурные скобки {}, который может записываться на нескольких строках.
Все переменные, используемые внутри макросов, являются глобальными. Т.е. они сохраняют свои значения при завершении макроса и, кроме того, являются общими для всех объявленных макросов. Типы переменных как и в языке Icon явно не специфированы, а определяются текущими значениями. Имена переменных и функций являются чувствительными к регистру символов.
Ниже дано краткое описание наиболее употребимых функций языка Icon с указанием типа входных параметров и возвращаемых значений. Используемые обозначения:
N - натуральное число; i - целое; r - вещественное; s - строка; c - множество символов; L - список значений (массив); x - любое значение; f - указатель на открытый файл ввода/вывода.
Подробное описание всех функций можно найти на домашней страничке Icon в Аризонском Университете https://www.cs.arizona.edu/icon/.
abs(N) : N |
вычисляет абсолютное значение |
acos(r1) : r2 |
вычисляет арк-косинус |
asin(r1) : r2 |
вычисляет арк-синус |
atan(r1,r2) : r3 |
вычисляет арк-тангенс r1/r2 |
cos(r1) : r2 |
вычисляет косинус |
dtor(r1) : r2 |
преобразует градусы в радианы |
rtod(r1) : r2 |
преобразует радианы в градусы |
exp(r1) : r2 |
вычисляет экспоненту |
iand(i1,i2) : i3 |
побитовое сложение |
icom(i1) : i2 |
побитовое дополнение |
integer(x) : i |
преобразует x в целое число |
ior(i1,i2) : i3 |
побитовое "включающее-или" |
ishift(i1,i2) : i3 |
сдвиг битов |
ixor(i1,i2) : i3 |
побитовое "исключающее-или" |
log(r1,r2) : r3 |
вычисляет логарифм |
numeric(x) : N |
преобразует значение в число |
real(x) : r |
преобразует x в вещественное значение |
sin(r1) : r2 |
вычисляет синус |
sqrt(r1) : r2 |
вычисляет квадратный корень |
tan(r1) : r2 |
вычисляет тангенс |
any(c,s) : i |
проверка первого символа строки на принадлежность заданному множеству символов (в случае успеха возвращает 1, иначе fail-прерывание) |
сset(s) : с |
преобразование строки в множество символов |
center(s,i) : s2 |
центрирует строку по ширине i |
left(s,i) : s2 |
сдвигает строку влево по ширине i |
left(s1,i,s2) : s3 |
возвращает строку шириной i символов, в которой s1 позиционируется слева и дополняется справа символами из s2; например, left("abc",5,"+") вернет "abc++" |
right(s,i) : s2 |
сдвигает строку вправо по ширине i |
right(s1,i,s2) : s3 |
возвращает строку шириной i символов, в которой s1 позиционируется справа и дополняется спереди символами из s2; например, right("abc",5,"+") вернет "++abc" |
ord(s) : i |
возвращает код символа |
char(i) : s |
возвращает символ по его коду |
find(s1,s2,i1) : i |
поиск подстроки s1 в строке s2 (возвращает позицию в s2, с которой начинается s1, иначе fail-прерывание); если указано значение i1, то поиск начинается с позиции i1, иначе с начала строки |
map(s1,c1,c2) : s4 |
трансляция символов строки s1, принадлежащих множеству символов c1, в соответствующие символы множества c2 |
many(c,s) : i |
проверка символов строки на принадлежность заданному множеству символов (возвращает позицию первого символа в s, не входящего в множество c, иначе fail-прерывание) |
match(s1,s2) : i |
проверка совпадения начала строки s2 с подстрокой s1 (в случае успеха возвращает 1, иначе fail-прерывание) |
upto(c,s) : i |
поиск в строке s символов из заданного множества c (в случае успеха возвращает позицию символа в строке s, иначе fail-прерывание) |
repl(s,i) : s2 |
реплицирует строку i раз |
reverse(s) : s2 |
обращает строку задом наперед |
string(x) : s |
преобразует x в строку |
trim(s) : s2 |
обрезает строку от крайних правых пробелов |
trim(s, с) : s2 |
обрезает строку с правого конца от символов, заданных множеством с |
Примечание: fail-прерывание вызывает откат выполнения оператора, в котором оно возникло. Это связано с логикой работы языка Icon, который поддерживает backtracking выполняемых операций (аналогично языку Prolog). В случае fail-прерывания текущая операция просто не выполняется. Например, следующий код
...
i := match("123", "qwerty")
write(i)
...
|
при выполнении вызовет fail-прерывание, в результате чего переменная i останется без значения.
list(i,x) : L |
создает список длиной i со значениями элементов x |
pop(L) : x |
выталкивает начальное значение из списка |
get(L) : x |
синоним pop() |
pull(L) : x |
выталкивает последнее значение из списка |
push(L,x1,x2,...,xn) : L |
добавляет значения к списку с начала |
put(L,x1,x2,...,xn) : L |
добавляет значения к списку с конца |
sort(L) : L |
сортирует список и возвращает упорядоченный список его значений |
sortf(L,i) : L |
сортирует список по заданному полю i, в том случае если элементы исходного списка также являются списками |
sortfiles(L) : L |
сортирует список имен файлов по значениям пути и имени |
asort(L) : L |
сортирует список строк в алфавитном порядке: результирующие строки приводятся к нижнему регистру, а первая буква делается заглавной |
set(L) : S |
создает множество из заданного списка L (множество отличается тем, что в нем все значения уникальные) |
sort(S) : L |
сортирует множество и возвращает упорядоченный список его значений |
table(x) : T |
создает таблицу T, инициализированную значениями ключей равными x |
table() : T |
создает таблицу T, инициализированную "пустыми" значениями ключей |
insert(T,x) : T |
добавляет в таблицу T ключ со значениям x; оператор T[x] := y задает соответствие ключа значению y |
delete(T,x) : T |
удаляет из таблицы T ключ x |
member(X,x) : x |
проверяет, содержит ли таблица T ключ x; возвращет x, если да или fail-прерывание в противном случае |
sort(T,i) : L |
сортирует таблицу T и возвращает упорядоченный список, каждое значение которого есть пара значений (ключ, значение) исходной таблицы. i=1 задает сортировку по значению ключа, 2 - по значению. |
close(f) : f |
закрывает файл |
getch() : s |
читает символ с клавиатуры |
getche() : s |
читает символ с клавиатуры с эхом |
kbhit() : n |
проверка нажатия клавиши |
open(s,"r") : f |
открывает файл на чтение |
open(s,"w") : f |
открывает файл на запись |
open(s,"a") : f |
открывает файл на запись в режиме добавления |
read(f) : s |
читает строку из файла |
reads(f,i) : s |
читает файл в буфер заданного размера i |
remove(s) : n |
удаляет файл с заданным именем s |
rename(s1,s2) : n |
переименовывает файл с s1 на s2 |
seek(f,i) : f |
позиционирует файл прямого доступа к i-ой позиции |
where(f) : i |
возвращает текущую позицию в файле |
write(x1,x2,...,xn) : xn |
выводит список значений с переводом строки |
writes(x1,x2,...,xn) |
выводит список значений без перевода строки |
exit(i) |
завершает работу утилиты с заданным кодом возврата |
chdir(s) : n |
смена текущей директории на s |
setenv(s1,s2) |
задает для системной переменной окружения s1 значение s2 (в рамках текущего процесса) |
getenv(s1) : s2 |
возвращает значение системной переменной окружения s1 |
stop(x1,x2,...,xn) |
прекращает выполнение утилиты и выводит заданный список значений |
system(s) : i |
вызывает системную функцию или программу, заданную именем s |
type(x) : s |
возвращает тип значения переменной x |
ReFind(s1,s2,i1) : i |
поиск в строке s2 подстроки, заданной регулярным выражением s1 (возвращает позицию такой подстроки в s2, иначе fail-прерывание); если указано значение i1, то поиск начинается с позиции i1, иначе с начала строки s2; специальные символы в s1 должны задаваться двойным символом \\, например, "\\w" вместо "\w" |
ReMatch(s1,s2,i1) : i |
проверка соответствия строки s2 шаблону, заданному регулярным выражением s1 (возвращает позицию, следующую за соответствующей подстрокой в s2, иначе fail-прерывание); если указано значение i1, то проверка начинается с позиции i1, иначе с начала строки s2; специальные символы в s1 должны задаваться двойным символом \\, например, "\\w" вместо "\w" |
roman(i) : s |
преобразования целого числа в строку, представляющее число в римской нотации: roman(21) вернет "XXI" |
unroman(s) : i |
преобразует значение числа в римской нотации в целое значение: unroman("XXI") вернет 21 |
julian(date) | смотри тут |
unjulian(date) | смотри тут |
В этом разделе описаны функции, расширяющие состав стандартных функций языка Icon.
| Операции обработки данных | |
set_encoding(s) |
задает формат кодирования обрабатываемых файлов (ANSI или UTF-8) |
set_option(s) |
задает опцию или параметр обработки, смотри п.4.4 |
load_script(s) |
передает управление скрипту, указанному спецификацией s |
execute_processing(L) |
задает обработку заданного списка файлов текущим скриптом |
add_input(s) |
задает спецификацию файла, который добавляется к совокупности обрабатываемых файлов |
set_input(s) |
задает спецификацию (маску поиска) совокупности обрабатываемых файлов |
open_input(s) |
задает спецификацию файла, который немедленно открывается на обработку (при этом обработка текущего файла завершается) |
read_input() : s |
возвращает следующую строку обрабатываемого файла, исключая ее из обработки |
read_input(i) : L |
возвращает список следующих i строк обрабатываемого файла; если i = 0, возвращает список всех строк обрабатываемого файла, начиная со следующей (при этом данные строки исключаются из обработки) |
close_input() |
закрывает текущий входной файл; при этом срабатывает маркер @eof, если он был задан |
tabto(i) : s |
осуществляет сдвиг к i-ой позиции текущей обрабатываемой строки @subject, что позволяет исключить из обработки начальные символы строки до позиции i; сдвиг к концу строки задается i=0; отрицательные значения i задают сдвиг в обратном направлении от конца строки |
eof() |
осуществляет быстрый переход в конец обрабатываемого файла и срабатывание маркера @eof, если он задан |
set_output(s) |
задает/перенаправляет вывод файлов результатов обработки по пути s |
open_output(s) |
открывает выходной файл с заданной спецификацией |
close_output() |
закрывает текущий выходной файл |
write_output(x1,...,xn) |
записывает в выходной файл список значений |
Обработка HTML элементов | |
diacritic(i) : s |
преобразование десятичного кода диактритичного символа ISO-8859-P1 в именованный HTML-символ, например, diacritic(192) вернет "À" |
greek(i) : s |
преобразование десятичного NCR Unicode для греческого в именованный HTML-символ, например, greek(913) вернет "Α" |
isEsc(s1) : s2 |
проверяет, является ли s1 именем именованного символа HTML 4.01; возвращает s1 если да, иначе fail-прерывание |
isTag(s1) : s2 |
проверяет, является ли s1 именем тега HTML 4.01; возвращает s1 если да, иначе fail-прерывание |
get_htmltitle(s) : s |
возвращает значение тега title HTML-документа, заданного url |
html2txt(s) : s |
преобразует размеченный текст в формате SGML/XML/HTML в обычный текст |
ncr2char(i) : с |
преобразования десятичного Unicode NCR в ANSI-символ; например, ncr2char(1040) для русской локали вернет букву А (\xC0) |
ncr2utf(i) : s |
преобразования десятичного Unicode NCR в мульти-байтовый символ UTF-8 |
Операции с датами | |
ExtractDate(str, fmt, months) : L |
выделение из строки str даты в заданном формате fmt. В составе fmt могут быть указаны следующие элементы:dd - порядковый номер дня месяца,mm - порядковый номер месяца,mon - наименование месяца,yy | yyyy - порядковый номер года.Необязательный параметр months задает массив наименований месяцев (могут использоваться рег.выражения).Возвращает массив из двух элементов: 1) выделенной даты в виде записи date_rec с полями (year, month, day, yearday, monthname, dayname) и 2) выделенной строки даты.
Например, ExtractDate("Наступило 5 Марта 1953 г.","dd mon yyyy") вернёт [(1953,3,5,64,"Monday","March"),"5 Марта 1953"].
Описание полей возвращаемой записи date_rec: year - год, month - месяц, day - день, yearday - номер дня с начала года, monthame - имя месяца, dayname - наименование дня недели. |
str2date(str, fmt, months) : R |
Преобразует строку str в дату по заданному формату fmt. Необязательный параметр months задает массив наименований месяцев. Возвращает запись date_rec с полями (year, month, day, yearday, monthname, dayname).
Например, str2date("23.5.1968","dd.mm.yyyy") вернет (1968,5,23,68,144,"Monday","May"). |
date2str(date, fmt, months) : s |
Преобразует дату date в строку по заданному формату fmt. Необязательный параметр months задает массив наименований месяцев. Дата кодируется как запись date_rec с полями (year, month, day, yearday, monthname, dayname). |
dateGt(d1, d2): int |
сравнение: дата d1 больше чем дата d2? Возвращает 1, если да. |
dateLt(d1, d2): int |
сравнение: дата d1 меньше чем дата d2? Возвращает 1, если да. |
dateEq(d1, d2): int |
сравнение: дата d1 равна дате d2? Возвращает 1, если да. |
dateBetween(d, d1, d2): int |
сравнение: дата d принадлежит интервалу (d1,d2)? Возвращает 1, если да. |
gregor2julian(d): d |
преобразует дату Григорианского календаря (н.ст.) в дату Юлианского календаря (ст.ст.). |
julian2gregor(d): d |
преобразует дату Юлианского календаря (ст.ст.) в дату Григорианского календаря (н.ст.). |
date_output(date) |
Печатает дату date, представленную записью date_rec с полями (year, month, day, yearday, monthname, dayname). |
IsYearLeap(year) : i |
проверка, является ли указанный год високосным? Возвращает 1, если год високосный и 0, если нет. |
julian(date) : i |
Вычисляет номер Юлианского дня для указанной даты, представленной как date_rec с непустыми полями (year, month, day).
Например, julian(str2date("23.5.1968","dd.mm.yyyy")) вернет 2440000.Смотри https://en.wikipedia.org/wiki/Julian_day |
unjulian(i) : R |
вычисляет дату по номеру Юлианского дня, возвращает запись date_rec с полями (year, month, day, yearday, monthname, dayname).
Например, unjulian(2440000) вернёт (1968,5,23,144,"May","Thursday"). |
Операции со строками | |
get_csv(s,delim) : L |
возвращает список значений L, сформированный из CSV-строки s (значения-через-разделитель); по умолчанию delim задает разделитель в виде фиксированного значения (например: ","); чтобы задать delim как набор альтернативных символов можно использовать функцию cset, например: cset(",;\t") |
get_length(s1) : i |
вычисления длины строки в символах (а не байтах); строка может содержать NCR и именованные HTML-символы |
length(x) : i |
возвращает длину строки в байтах или размер структуры x |
len(x) : i |
синоним функции length(x) |
like(s1,s2) : i |
проверяет строку s1 по заданной поисковой маске s2 (возвращает 1, если строка соответствует маске, иначе fail-прерывание); в состав маски могут входить символ звездочки (*), задающий любую строку символов и символ подчеркивания (_), задающий одиночный символ |
likeword(s) : i |
проверяет, похожа ли подстрока s в составе текущей строки @subject на слово, т.е. состоит из букв и ограничена символами разделителями (возвращает 1, если да, иначе fail-прерывание) |
lower(s1) : s2 |
преобразует строку в нижний регистр |
ltrim(s1) : s2 |
удаляет из начала строки символы пробела |
ltrim(s1,c) : s2 |
удаляет из начала строки s1 символы, заданные множеством c |
replace(s,s0,s1) : s2 |
заменяет в строке s все появления подстроки s0 на s1 |
replace_first(s,s0,s1) : s2 |
заменяет в строке s только первый экземпляр подстроки s0 на s1 |
Replace(s,s0,s1) : s2 |
заменяет в строке s все появления подстроки s0, заданной регулярным выражением, на подстроку s1, также заданной регулярным выражением.
Например, Replace("8-го марта", "\\dd(\\dd)?-го", "\\dd(\\dd)?") вернет "8 марта" |
sql_quotes(s1) : s2 |
заменяет каждый одиночный символ апострофа (') внутри строки на двойной ('') |
substr(s1,i1,i2) : s2 |
возвращает подстроку с i1-ой позиции s1 и длиной i2 символов; если i2 опущено, то до конца строки s1 |
upper(s1) : s2 |
преобразует строку в верхний регистр |
str2utf(s1) : s2 |
преобразование строки ANSI-символов в строку UTF-8 |
utf2ncr(s1) : s2 |
преобразование строки в формате UTF-8 в строку символов Unicode NCR (&#DDDD;) |
utf2str(s1) : s2 |
преобразование строки в формате UTF-8 в ANSI-строку (непреобразуемые символы кодируются как Unicode NCR и HTML именованные символы) |
utf8_upper(s1) : s2 |
преобразование строки в формате UTF-8 к "верхнему регистру" (заглавным буквам) |
utf8_lower(s1) : s2 |
преобразование строки в формате UTF-8 к "нижнему регистру" (прописным буквам) |
Файловые операции | |
dir_exists(s) : i |
проверяет существование папки, указанной путем s; возвращает 1, если папка существует, иначе 0 |
make_dir(s) : i |
создает папку, указанную путем s, если она не существует |
file_exists(s) : i |
проверяет существование файла, указанного путем s; возвращает 1, если файл существует, иначе 0 |
get_content(s) : L |
возвращает список непустых строк заданного файла (аналог макроопределения @read) |
getext(s1) : s2 |
возвращает тип файла по его спецификации, например в UNIX getext("/home/work/file.txt") вернет "txt" |
getname(s1) : s2 |
возвращает имя файла по его спецификации, например в UNIX getname("/home/work/file.txt") вернет "file" |
getpath(s1) : s2 |
возвращает путь по спецификации файла, например в UNIX getpath("/home/work/file.txt") вернет "/home/work/" |
get_separator() : c |
возвращает символ-разделитель, используемый в файловых путях |
listfiles(s,i) : L |
возвращает список файлов по заданной маске s; второй параметр - необязательный, если он задан равным 1, то список формируется рекурсивным обходом всех вложенных папок |
Графические операции | |
Hist(T, title, options) |
визуализация гистограммы, заданной структурой T (таблицей или списком). Если T список, то каждое его значение должно быть 2-х или 3-х мерным массивом: первый элемент задает категорию, второй частоту, а третий цвет (опционно). Необязательные параметры title - заголовок графического окна; options - строка параметров графического окна. Смотри п.8.20. |
PlotWords(T, title, options) |
визуализация списка слов, заданных структурой T (таблицей или списком). Если T список, то каждое его значение должно быть 2-х или 3-х мерным массивом: первый элемент задает категорию, второй частоту, а третий - цвет (опционно). Необязательные параметры title - заголовок графического окна; options - строка параметров визуализации. Смотри п.8.21 |
Прочие операции | |
hex2int(s) : i |
преобразует 16-ричный символ в целое, например hex2int("ff") вернет 255 |
lfind(L,x) : i |
поиск элемента списка L со значением x (любого типа); возвращает порядковый номер такого элемента или 0 |
EOL(s) : s |
задает (возвращает) формат конца строки: EOL("win") или EOL("\xD0\xA0") для Windows; EOL("unix") или EOL("\xA0") для Unix; EOL("mac") или EOL("\xD0") для Mac |
isnull(x) : i |
возвращает 1, если x не имеет никакого значения, иначе 0 |
notnull(x) : i |
возвращает 1, если x имеет какое-либо значение, иначе 0 |
rand() : r |
возвращает псевдослучайное значение в диапазоне (0.0,1.0) |
rand(n) : i |
возвращает псевдослучайное значение в диапазоне (1,n) |
Gauss(m,f) : r |
возвращает псевдослучайное значение нормального закона распределения (m-среднее, f-стандартное отклонение). Эта функция основана на функции gauss.icn из библиотеки IPL |
wt(L1,L2,L3) : L |
возвращает список слов, сгенерированных модулем анализа текстов wordtabulator. L1 задает список обрабатываемых файлов. Необязательный параметр L2 задает список файлов исключений. Необязательный параметр L3 задает список опций обработки. |
Счетчики используются, когда необходимо выполнить динамическую разметку, зависящую от порядковых номеров обрабатываемых элементов текста. Например, используя счетчики, можно связать навигационными гиперссылками массив html-документов, имена которых содержат порядковые номера.
Количество счетчиков никак не ограничено, а их параметры (начальное значение, тип и приращение) задаются в секции [Options]. Счетчики могут быть двух типов - относительными или абсолютными. Относительные счетчики в отличие от абсолютных автоматически инициализируются при открытии каждого очередного обрабатываемого файла.
Значения i-го счетчика может быть подставлено в шаблоне замены с помощью макроопределения @counter(i) или вызвано в теле макроса с помощью переменной counter[i]. Макроопределение @counter(i)
возвращает текущее значение i-го счетчика и, если задан режим автоинкрементации (autoincr=true), автоматически увеличивает его на приращение. При выключенном режиме автоинкрементации (autoincr=false) приращение i-го счетчика может быть
задано в шаблоне замен с помощью макроопределения @next(i). Это макропределение не возвращает никакого значения, а только выполняет приращение счетчика. В теле макроса инкрементацию счетчика можно задать с помощью оператора:
counter[i] := counter[i] + counterIncr[i]
Для ручной инициализации i-го счетчика в шаблоне замен может быть использовано макроопределение @reset(i). Это макроопределение не возвращает никакого значения, а только устанавливает счетчик в начальное значение. В теле макроса инициализацию счетчика можно задать с помощью оператора:
counter[i] := counterInit[i]
Макроопределения могут использоваться при задании стартовых или стоповых маркеров, в шаблонах замены, а также в процедурных макросах. Макроопределение может определять некоторое символьное значение, набор символов или текущую позицию обработки.
@ascii |
множество 128 символов ASCII-7 |
@blank |
список пустых символов [@sp, @tab, " "] |
@body |
подстрока между стартовым и стоповым маркерами |
@bof |
начало исходного файла |
@bol |
начало текущей строки исходного файла |
@call name |
вызывает выполнение макро-процедуры name из тела другой макро-процедуры; это не вызов в чистом виде, а нечто вроде вставки куска кода |
@clcase |
множество 33 строчных русских букв Win-1251 |
@cletters |
синоним @cp1251 |
@clock |
текущее время в формате "ЧЧ:ММ:СС" |
@counter |
текущее значение 1-го счетчика; нельзя использовать в макро-процедурах и внутри @eval() |
@counter(i) |
текущее значение i-го счетчика; нельзя использовать в макро-процедурах и внутри @eval() |
@cp1251 |
множество русских букв в кодировке Win-1251 |
@cp866 |
множество русских букв в кодировке DOS-866 |
@cset |
множество 256 символов ASCII-8 |
@cset(s) |
множество символов, заданных строкой в кавычках |
@cucase |
множество 33 заглавных русских букв Win-1251 |
@date |
текущая дата в формате "ГГГГ/ММ/ДД" |
@dateline |
строка текущих даты-времени, например: "Thursday, May 4, 2023 5:06 am" |
@digits |
множество цифр {0-9} |
@eof |
конец исходного файла |
@eol |
конец текущей строки исходного файла |
@e |
значение числа e = 2,71... |
@eval(s) |
вычисляет и подставляет значение символьного выражения s |
@include file |
вставляет содержимое файла file в тело макро-процедуры |
@features |
список[] характеристик, поддерживаемых текущей реализацией утилиты |
@file |
спецификация текущего обрабатываемого файла |
@fileno |
порядковый номер файла в списке обрабатываемых файлов |
@host |
имя компьютера |
@input |
спецификация текущего обрабатываемого файла (синоним @file) |
@INPUT |
список ВСЕХ файлов, подлежащих обработке |
@letters |
множество букв латинского алфавита |
@lcase |
множество 26 строчных латинских букв |
@line |
значение текущей строки исходного файла |
@lineno |
порядковый номер текущей строки в файле |
@next(i) |
генерирует следующее значение i-го счетчика |
@nfiles |
общее число обрабатывемых файлов |
@nl |
символ перевода строки |
@null |
пустое значение |
@output |
спецификация текущего выходного файла |
@OUTPUT |
список ВСЕХ результирующих файлов (этот спиок увеличивается по мере обработки) |
@pi |
значение числа пи = 3,14... |
@pos |
позиция сдвига в подстроке @subject, задаваемая с помощью функции tabto(i) |
@q |
символ двойной кавычки |
@read(s) |
формирует список всех непустых строк файла s (имя файла задается без кавычек) |
@regexp(s) |
поисковый шаблон в виде регулярного выражения, заданного строкой s |
@reset(i) |
сбрасывает i-ый счетчик в начальное значение |
@run(s) |
выполняет процедурный макрос s и подставляет возвращаемое им значение |
@script |
спецификация текущего скрипта обработки |
@stepno |
номер шага обработки: инициализируется 0 и увеличивается на 1 при каждом вызове execute_processing |
@source |
спецификация совокупности исходных файлов, заданная параметром -f командной строки или процедурой set_input() |
@semicolon |
символ точки с запятой (;) |
@space |
символ пробела |
@sp |
символ пробела (синоним @space) |
@start |
значение текущего стартового маркера |
@stop |
значение текущего стопового маркера |
@subject |
остаток текущей обрабатываемой строки, начиная с позиции за стоповым маркером и до конца исходной строки |
@tab |
символ табуляции |
@target |
путь сохранения результирующих файлов, заданный параметром -o командной строки или процедурой set_output() |
@time |
текущее время выполнения программы в миллисекундах |
@ucase |
множество 26 заглавных латинских букв |
@version |
текущая версия утилиты |
Примеры использования макроопределений в составе выражений:
| i := match(@sp,@line) | возвращает 1, если строка начинается пробелом |
| i := any(cset("abc"),@line) | возвращает 1, если строка начинается буквами "a","b" или "c" |
| i := upto(@ucase,"an ExamplE") | возвращает позицию первой заглавной буквы в строке (4) |
| i := many(@ucase,"") | возвращает позицию после начальной последовательности заглавных букв в строке (4) |
| s := map(@line,"abc","123") | преобразует символы "a","b","c" в составе текущей строки на "1","2","3" |
| ( @lineno <= 10 ) | истинно для первых 10 строк обрабатываемого файла |
| like(@line,"Ах*!") | истинно для строк, начинающихся на "Ах" и оканчивающихся восклицательным знаком |
| s := tabto(0) | осуществляет сдвиг к концу текущей строки (эта часть строки, запоминаемая в переменной s, пропускается из дальнейшей обработки) |
Примечание. Макроопределения, задающие множество значений или позицию (кроме макроопределения @read(s)), не могут использоваться в шаблонах замен. Имена макроопределений как и имена переменных и функций чувствительны к регистру.
Макроопределение пустой строки @null может использоваться в трех случаях.
1. Для задания маркеров, начинающихся символами решетки "#", точки с запятой ";" (это символы используются как начало комментариев в файле параметров) или открывающей квадратной скобки "[" (так начинаются секции), например:
[startEntity] ; если маркер начинается символом решетки @null#01 ; если маркер начинается точкой с запятой @null;01 ; eсли маркер начинается открывающей квадратной скобкой @null[01] |
2. Для задания поиска текста только по одному маркеру - либо стартовому, либо стоповому. Например, поиск подстроки "abc" может быть задан как:
# поиск по стартовому маркеру [startEntity] abc [stopEntity] @null |
или
# поиск по стоповому маркеру [startEntity] @null [stopEntity] abc |
3. В шаблоне замены для задания вырезки найденного текста. Т.е. если указать в качестве шаблона замены @null, то подстрока <старт-маркер><тело><стоп-маркер> окажется вырезанной в результирующем тексте.
Специальные символы используются внутри строковых констант (в макросах) и задаются в виде 2-символьных последовательностей, начинающихся символом обратной косой черты (\).
| \\ | символ обратной косой черты |
| \" | символ двойной кавычки |
| \q | то же, что и \" |
| \n | символ перевода строки (аналог @nl) |
| \t | символ табуляции (аналог @tab) |
| \r | символ возврата каретки |
| \f | символ перехода на новую строку |
| \xnnn | символ, заданный 16-ричным кодом nnn |
Примеры.
s := "\"эта строка будет выведена в кавычках\"" write_output(s,"\n") |
Начиная с версии 2.0 утилиты добавлена возможность использования регулярных выражений при задании стартовых/стоповых маркеров. Данная возможность реализована в результате интегрирования в ядро утилиты процедуры regexp.icn, разработанной Робертом Александером (Robert J. Alexander) и входящей в состав публичной библиотеки программ Icon.
Регулярное выражение задается с помощью макроопределения @regexp(s), например: @regexp("[0-9]*\.[0-9]+"). Смотри главу Примеры, в которой демонстрируется использование регулярных выражений.
В целом формат используемых регулярных выражений очень близок к формату, поддерживаемому UNIX-утилитой "egrep", с учетом расширений для языка Perl. Ниже дается краткое описание специальных символов, используемых в составе регулярных выражений (РВ).
| c | Любой обычный символ (т.е. ни один из числа, описанных ниже), задающий в РВ сам себя | \c | Обратный слэш с последующим символом задает специальный символ (например, \t). Обычно это какой-то непечатный символ |
| . | Точка в составе РВ задает любой одиночный символ; сам символ точки должен быть задан c обратным слэшем впереди (\.) |
| [строка] | Непустая строка символов, заключенная в квадратные скобки, задает совпадение с любым одним символом из указанных в строке. Если первый символ "^", это задает сопадение с любым символом, исключая указанные в строке. Символ "-" между двумя символами задает диапазон последовательных ASCII символов, например, [0-9] эквиавалентно [0123456789]. Другие специальные символы в составе строки задают сами себя. |
| * | Задает сопадение с 0..* экземплярами выражения, указанного слева |
| + | Задает сопадение с 1..* экземплярами выражения, указанного слева |
| ? | Задает сопадение с 0..1 экземплярами выражения, указанного слева |
| {N} | Задает сопадение точно с N экземплярами выражения, указанного слева |
| {N,} | Задает сопадение с минимум N экземплярами выражения, указанного слева |
| {N,M} | Задает сопадение с минимум N но не более M экземплярами выражения, указанного слева |
| ^ | Символ крышечки в начале РВ задает совпадение с началом строки |
| $ | Символ доллара в конце РВ задает совпадение с концом строки |
| | | Вертикальная черта задает альтерацию выражений записанных слева и справа |
| () | РВ в круглых скобках задает группу |
| \N | Где N - цифра в диапазоне 1-9, задает повторение N раз выражения в круглых скобках слева. Например, ^(.*)\1$ задает строку, состоящую из двух одинаковых последовательностей символов. |
Ниже приводится описание расширенных символов, поддерживаемых языком Perl. Эти символы могут указываться в составе выражений в квадратных скобках [].
| \w | Задает любой буквенно-цифровой символ, включая символ подчеркивания "_" |
| \W | Любой не буквенно-цифровой символ |
| \b | Задает границу слова, заданного последовательностью буквенно-цифровых символов \w; т.е. начало или конец строки, знак препинания или символ промежутка. |
| \B | Любая не-словесная граница |
| \s | Задает любой символ промежутка |
| \S | Не символ промежутка |
| \d | Любая цифра [0-9] |
| \D | не цифровой символ |
Следует понимать, что некоторые регулярные выражения неоднозначно понимаются для ANSI и UTF-8 данных. Это происходит из-за того, что используемые регулярные выражения предназначены для обработки одно-байтовых символов ANSI, а в UTF-8 "символы" кодируются последовательностью от 1 до 4-х байтов. Например, выражение [А-яЁё] для ANSI задает буквы кириллицы, а для UTF-8 вовсе нет. В последнем случае нужно явно перечислить все буквы алфавита [АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЧЦШЩЬЪЫЭЮЯабвгдеёжзийклмнопрстуфхчцшщьъыэюя]. Точно также точка в составе выражения (.), задающая одиночный символ, сработает только для 1-байтовых UTF-8 символов (ASCII). Однако такие специальные символы как \b или \w обрабатываются правильно и для UTF-8.
Макроопределение @subject задает конец текущей обрабатываемой строки, начиная с позиции за стоповым маркером. Макроопределение @pos задает позицию сдвига в @subject (по умолчанию 1). Сдвиг задается с помощью функции tabto(i), где i - позиция сдвига. Сдвиг позволяет пропустить из последующей обработки начало строки @subject до позиции i. Если необходимо исключить из обработки всю строку @subject, то позиция сдвига задается как 0. Если позиция сдвига указывается отрицательной, это означает сдвиг к i-ой позиции, начиная с конца строки. Например, tabto(3) задает пропуск первых двух символов строки @subject; tabto(-1) задает сдвиг до последнего символа строки; tabto(-3) - задает сдвиг до третьего символа с конца. Смотри пример 8.5, в котором показано использование функции сдвига.
Использование этих операторов имеет свои нюансы, поэтому имеет смысл рассмотреть их на простых примерах. Пусть мы имеем массив или список значений, которые необходимо каким-либо образом обработать. Для этого нам пригодятся операторы цикла while или every - какой больше нравится.
Оператор while в качестве проверяемого условия может использовать любое выражение, возвращающее числовые значения. Проверка условия дает true, если значение выражения не равно 0, иначе false. Например,
# распечатаем список значений с помощью оператора цикла while array := ["a","b","c"] i := 0 while i < len(array) do write( array[i := i + 1] ) |
Как это ни странно, но логическое выражение i < len(array) возвращает 1, если условие истинно и 0 в противном случае. Такое уж принято соглашение для логических условий. К слову, выражение while 1 do ... задает выполнение бесконечного цикла.
Другой вариант использования while для обработки списка. В этом случае используется функция get(), которая возвращает очередной элемент списка с одновременным его удалением из списка. После выполнения цикла исходный список станет пустым. Например,
# распечатаем список значений с помощью оператора цикла while array := ["a","b","c"] while len(array)>0 do write( get(array) ) # array после этого станет пустым |
При использовании оператора every задается интервал целых значений, определяющий число повторений цикла. Например, every 3 to 5 задает длину цикла равным 3 (т.е. цикл выполняется для значений 3,4,5). В качестве границ интервала можно задавать любые выражения, возвращающие целые значения. Ниже приведен пример задания цикла с помощью оператора every:
# распечатаем список значений с помощью оператора цикла every array := ["a","b","c"] i := 0 every 1 to len(array) do write(array[i := i + 1]) |
Файлы, которые открываются на чтение/запись в процессе обработки из тела макро-процедур, например:
procedure initialize
in := open("infile.txt", "r")
out := open("outfile.txt", "w")
...
# сформируем массив строк
t := get_content("infile.txt")
# или
t := list()
while notnull(s := read(in)) do put(t,s)
...
close(in)
end
|
по умолчанию читаются/создаются по пути размещения текущего файла правил обработки. Т.е. папка файла правил обработки всегда задает рабочую папку. Разрешается также использовать относительные пути, которые указываются относительно этой рабочей папки. Естественно, можно использовать полные пути к файлам, тогда они могут размещаться в любом месте. Сказанное также справедливо для макропределения @read(file).
Строка s, содержащая текст в любой национальной 2-х байтовой кодировке, может быть перекодирована с помощью функции map(s,srcenc,trgenc), где srcenc - множество символов исходной кодировки, а trgenc - множество символов целевой кодировки. Используя макропределения @cp1251 и @cp866, задующие множество кириллических букв в кодировках Win-1251 и DOS-866, мы можем:
# перекодировать строку s из Win-1251 в DOS-866 s := map(s, @cp1251, @cp866) # перекодировать строку s из DOS-866 в Win-1251 s := map(s, @cp866, @cp1251) |
Чтобы преобразовать ANSI строку в UTF-8 используете функцию str2utf:
# перекодировать строку Win-1251 в UTF-8 s := str2utf(s) # перекодировать строку Win-1252 в UTF-8 s := str2utf(s,"windows-1252") |
Часто один и тот же скрипт может использоваться для разных входных данных, поэтому может потребоваться задание пользовательских параметров. Естественно, это можно сделать прямо внутри скрипта. Но тогда каждый раз будет неоходимо модифицировать текст скрипта. Можно выйти из этой ситуации несколькими способами.
write("задайте входной параметр P1=")
p1 := read()
write("задайте входной параметр P2=")
p2 := read()
|
procedure initialize
@include \examples\param.txt
end
...
# включаемый файл может содержать любые конструкции в формате макро-языка:
p1 := 10
p2 := 2
|
> set p1=10
> set p2=2
> xm.exe -f*.html -ptest.par
# значения переменных среды читаются в скрипте test.par:
p1 := getenv("p1")
p2 := getenv("p2")
|
Начиная с версии 4.1 можно задавать переменные окружения, передаваемые в скрипт, непосредственно в GUI.
Иногда обработка исходных файлов должна включать в себя несколько различных шагов, например,
Естественно, каждый шаг обработки достаточно просто реализовать с помощью отдельного скрипта. При этом весь процесс обработки должен быть организован таким образом, чтобы результаты очередного шага подавались в качестве входных данных следующего шага. При увеличении числа требуемых шагов быстро нарастает сложность организации такого процесса. В версии 3.3 появилась возможность реализации конвейера обработки данных с неограниченным числом шагов. Для этого в процедуре finalize текущего скрипта нужно задать скрипт следующего шага обработки и список обрабатываемых файлов:
Если список обрабатываемых файлов на следующем шаге должен включать все полученные на текущем шаге результирующие файлы, то можно использовать макроопределение @OUTPUT.
Ниже показан механизм формирования списка файлов для следующего шага, использующий функцию set_output(). Алгоритм следующий:
FILES;FILES.Пример:
# скрипт step01.par (шаг 01)
#
[startentity]
@bof
...
[startmarkup]
@run(bof)
...
[options]
syncStop=true
syncMarkup=true
[macros]
procedure initialize
FILES := []
end
procedure bof
# перенаправим вывод результатов обработки тек.файла в указанную папку
set_output("d:\\work\\data\\step01")
# добавим тек.файл результатов в список
put(FILES, @output)
end
...
procedure finalize
# зададим кодировку обрабатываемых файлов на след.шаге
set_encoding("UTF-8")
# загрузим скрипт step02.par
load_script("step02.par")
# запустим обработку списка результирующих файлов скриптом step02.par
execute_processing(FILES)
end
|
Начиная с версии 3.4 в связи с переключением на язык программирования Unicon утилита стала способна работать с базами данных. Взаимодействие с целевой базой данных осуществляется с помощью соответствующего драйвера ODBC. В случае использования MySQL процесс установки драйвера и настройки подключения к базе данных для различных платформ подробно описан в документации, доступной on-line.
Предположим, мы сконфигурировали источник данных с именем mysql, именем пользователя user01 и паролем 123. Проверить доступ к созданному источнику из утилиты можно с помощью простого скрипта:
[Macros]
procedure initialize
if notnull(db := open("mysql","o","user01","123")) then write("Успешное подключение!") else stop("Ошибка подключения!")
close(db)
exit(0)
end
|
Работа с базами данных на языке Unicon с помощью языка запросов SQL прекрасно описана в книге Programming with Unicon. Смотри также примеры 8.18 и 8.25.
Начиная с версии 4.0, xMarkup был интегрирован с модулем анализа текстов, ранее развивавшемся в рамках отдельного проекта wordTabualtor.
Теперь обработку текстов можно задавать прямо из xMarkup скрипта с помощью вызова функции wt(F, E, opts), где
Функция wt возвращает список полученных слов и их частоты. Каждый элемент возвращаемого списка представляет собой пару значений (слово, частота).
Подробное описание опций wordtabulator можно найти в документе Программа WordTabulator. Руководство пользователя. За редким исключением все эти опции были портированы в xMarkup.
Каждая опция задается строкой в формате параметр=значение:
Примечания:
Координаты представляют собой список 3-х значений: порядковый номер элемента в тексте, номер элемента в составе фразы, номер соответствующего предложения.
Смотри примеры 8.20 и 8.21 использования модуля wordTabulator.
Утилита работает подобно конечному автомату. Инструкциями перехода автомата из одного состояния в другое являются заданные поисковые шаблоны и правила преобразования текста. На вход поступает входной текст, на выходе генерируется преобразованный текст. Опишем вкратце алгоритм работы утилиты:
| 1. | Открываем очередной файл из списка обрабатываемых файлов. Если список исчерпан, завершаем работу. |
| 2. | Читаем очередную строку файла и встаем в ее начало. Если достигнут конец файла, возвращаемся на шаг 1. |
| 3. | Если достигнут конец строки, возвращаемся на шаг 2. |
| 4. | Из заданного списка стартовых маркеров выбираем маркер, располагающийся ближе остальных к текущей позиции и имеющий наибольшую длину. Если в текущей строке таких маркеров не существует, возвращаемся на шаг 2. |
| 5. | Перемещаемся в позицию за стартовым маркером и выводим текст до маркера "как есть". |
| 6. | Если задана опция syncStop=true, то ищем с текущей позиции стоповый маркер, имеющий тот же порядковый номер в списке, что и найденный стартовый маркер. Иначе из заданного списка стоповых маркеров выбираем маркер, встречающийся ближе остальных к текущей позиции. |
| 7. | В случае успешного завершения шага 6 в текущей строке переходим на шаг 8. Иначе читаем очередную строку, встаем в ее начальную позицию и возвращаемся на шаг 6. |
| 8. | Если задана опция syncMarkup=true, то выбираем шаблон замен, который имеет тот же порядковый номер в списке, что и найденный стартовый маркер. Иначе выбираем первый шаблон из списка. Выводим текст в соответствии с шаблоном замен, сдвигаемся в позицию за стоповым маркером и возвращаемся на шаг 3. |
При поиске стартовых/стоповых маркеров важную роль при прочих равных условиях играет их приоритет.
Перечислим маркеры в порядке убывания их приоритета:
Ниже приведен список имеющихся ограничений утилиты:
1. Стартовый маркер должен находиться целиком в пределах одной строки, иначе он будет не найден.
2. Стоповый маркер также должен находиться в пределах одной строки обрабатываемого текста.
3. В определении стартового/стопового маркера можно указывать только единственное макроопределение, задающее множество символов. И более того, ничего другого в такое определение входить не должно. Так, например, значение @digits@letters будет неверным. Это ограничение можно легко обойти, используя регулярные выражения или процедурные макросы.
4. Необходимость задания оператора if ... then ... else ... в одной строке. Это ограничение можно частично снять, используя блоковую конструкцию, например:
if i = 1 then s := "один" else {
if i = 2 then s := "два" else {
if i = 3 then s := "три" else s := ""
}
}
}
|
5. Невозможность задания сложных логических условий с использованием логических операторов or, and, not.
6. Значение выражения, заданного в операторе if или while в качестве проверяемого условия, должно быть целого типа (0 = false). Так, например, выражение
while s := read() do write(s)
породит Run-time ошибку, если считанное значение s не число. Для проверки конца чтения следует использовать функцию notnull:
while notnull(s := read()) do write(s).
7. Макроопределение @bof может быть задано только для стартового маркера.
8. В силу особенностей реализации утилиты (интерпретатор "в квадрате") ее производительность заведомо ниже производительности исполнимого кода C или C++.
В качестве примеров приведены распечатки файла параметров утилиты для разных случаев преобразования исходного текста.
# conv2txt.par
# Удаление из документа XML/SGML/HTML разметки
[startEntity]
@regexp("<(no)?script")
@regexp("<(/)?(\w)+")
<!doctype
<!--
[stopEntity]
@regexp("</(no)?script>")
>
>
-->
[startMarkup]
@null
[Options]
syncStop = true
ignoreCase = true
|
Ниже приведен более простой вариант скрипта, использующий функцию html2txt(s).
# преобразование html=>text [startentity] @bol [stopentity] @eol [startmarkup] @eval(html2txt(@line)) |
# compact.par # Вырезка из текста пустых строк [Options] addNewLine = false [startEntity] @bol [stopEntity] @eol [startMarkup] @eval(if len(trim(@line,' \t')) > 0 then @line||@nl) |
# headers.par # Вставка в текст верхнего и нижнего колонтитулов [StartEntity] @bof @eof [StartMarkup] <!-- Это верхний колонтитул файла @file -->@nl <!-- Это нижний колонтитул файла @file --> [Options] syncMarkup = true |
# Разметка слов в предложениях с использованием регулярных выражений.
# Предложение заканчивается точкой, восклицательным или вопросительным знаком.
# символ \b задает границу слова - т.е. начало или конец строки, знак препинания или символ промежутка.
# символ \w задает любой буквенно-цифровой символ.
[startentity]
@regexp("\b\w+")
@regexp("[\.!?]")
[startmarkup]
@run(word)
@run(end_of_sentence)
[options]
syncMarkup=true
[macros]
macro initialize
sentence_counter := 0
word_counter := 0
is_end_sentence := 1
end
# очередное слово
procedure word
# если мы в начале предложения
if is_end_sentence then {
sentence_counter := sentence_counter + 1
word_counter := 0
write("<sentence id=\"",sentence_counter,"\">")
}
word_counter := word_counter + 1
write("<word id=\"", sentence_counter, ".", word_counter, "\">", @start, "</word>")
is_end_sentence := 0
end
# достигли конца предложения
procedure end_of_sentence
write("</sentence>")
is_end_sentence := 1
end
|
Мама мыла раму, папа пил вино, дети играли на улице. |
<sentence id="1"> <word id="1.1">Мама</word> <word id="1.2">мыла</word> <word id="1.3">раму</word>. <word id="1.4">папа</word> <word id="1.5">пил</word> <word id="1.6">вино</word>. <word id="1.7">дети</word> <word id="1.8">гуляли</word> <word id="1.9">на</word> <word id="1.10">улице</word>. </sentence> |
# trim.par # Удаление из текста излишних промежутков [StartEntity] @regexp([\s]+$) @regexp([\s]+) [StartMarkup] @null @sp [Options] syncmarkup=true |
В данном примере множество обрабатываемых текстов объединяется в один выходной файл, имя которого запрашивается в начале (по умолчанию, unite.dat). После завершения обработки печатается количество строк, записанных в выходной файл. В этом примере можно наглядно увидеть преимущества использования макро-процедур initialize и finalize.
# unite.par
# Склейка текстовых файлов в один выходной файл.
[StartEntity]
@eol
[StartMarkup]
@run(line)
[macros]
macro initialize
writes("Выходной файл [unite.dat]: ")
if (s:= read()) == "" then s := "unite.dat"
f := open(s,"w")
rows := 0
end
macro line
write(f,@line)
rows := rows + 1
end
macro finalize
write(rows, " строк записано в ",s)
end
|
Незамысловатый сриптик преобразования FictionBook формата fb2 в html.
# fb2html.par
# Преобразование e-book fb-файлов в html
[startEntity]
<?xml
<FictionBook
<description>
<a@sp
<title>
<binary
<section
<subtitle
<emphasis>
</emphasis>
<strong>
</strong>
</a>
<empty-line/>
</section>
<poem>
</poem>
<stanza>
</stanza>
<v>
</v>
<strikethrough>
</strikethrough>
</FictionBook>
[stopEntity]
?>
>
</description>
>
</title>
</binary>
>
</subtitle>
@null
[startMarkup]
@run(get_encoding)
@run(bof)
<!--@start@body@stop-->
@run(get_href)
@run(title)
@run(binary_data)
<div@body>
@run(title)
<b>
</b>
<b>
</b>
</a></sup>
<p></p>
</div>
<span class="poem">
</span>
<span class="stanza">
</span>
<span class="v">
<br></span>
<del>
</del>
@run(eof)
[Options]
syncStop = true
syncMarkup = true
[Macros]
procedure initialize
encoding := "utf-8"
end
procedure get_encoding
s := @body
if (i := find("encoding=",s))>0 then {
s := ltrim(substr(s,i+9))
encoding := substr(s,2,find(s[1],s,2)-2)
}
end
procedure bof
close_output()
file := getpath(@input)||getname(@input)||".html"
open_output(file)
write_output("<html><head>\n")
write_output("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=",encoding,"\">\n")
write_output("<style>span.v { color : blue; font-style: italic; text-align: right }</style>\n")
write_output("</head>\n")
end
procedure title
s := "<h4"||@body||"</h4>"
while (i := find("<a ",s)) do {
j := find(">",s,i)
t := substr(s,i,j-i+1)
write_output(substr(s,1,i-1),"<a href=",substr(t,find("href=",t)+5))
s := substr(s,j+1)
}
write_output(s)
end
# Base64 encoded image
procedure binary_data
s := @body
if (i := find("content-type=",s))>0 then {
s := substr(s,i+14)
j := find('"',s)
t := substr(s,1,j-1)
j := find(">",s)
s := substr(s,j+1)
write_output("<image src=",@q,"data:",t,";base64,",s,@q,">")
}
end
procedure get_href
s := @body
write_output("<sup><a href=",substr(s,find("href=",s)+5),">")
end
procedure eof
write_output("</html>")
close_output()
eof()
end
|
Простенький пример сортировки совокупности текстовых строк.
# sort.par # Сортировка строк множества обрабатываемых текстов. # Результирующая совокупность упорядоченных строк выводится на консоль. [startentity] @bol [startmarkup] @run(line) [macros] macro initialize # создадим пустой список p := list() end macro line # занесем в список очередную строку put(p, @line) end macro finalize # отсортируем список строк и выведем его на консоль # вместо процедуры sort() можно использовать asort(), # тогда строки упорядочатся строго в алфавитном порядке p := sort(p) while len(p) > 0 do write(get(p)) end |
В данном примере распечатывается список имен разметочных тегов, использованных в обрабатываемых XML/SGML/HTML документах.
С помощью Icon-функции set(), заданной в процедуре finalize, отсекаются все повторяющиеся имена.
# list_tags.par
# Печать списка имен тегов, использованных в xml/sgml/html документах.
# Закомментированный текст внутри <!-- ... --> игнорируется.
[startentity]
<
<!--
[stopentity]
>
-->
[startmarkup]
@run(tag)
@null
[Options]
syncStop=true
syncMarkup=true
[macros]
procedure initialize
p := list()
end
procedure tag
t := lower(@body)
if match("/", t) then return
if (i := upto(" \t\n",t)) > 0 then t := substr(t,1,i-1)
put(p, t)
end
procedure finalize
p := sort(set(p))
while len(p) > 0 do write(get(p))
end
|
# count-lines.par # Подсчет числа строк в текстовом файле. Печатает текущее время и число строк в файле. [startentity] @eof [startmarkup] @eval(write(@date||" "||@clock,"\t", @lineno)) |
Скрипт загрузка файла из Интернет по протоколу HTTP/HTTPS. При желании для этого можно использовать прекрасную утилиту curl, портированную на кучу платформ (curl теперь включена в состав Windows).
# download file by HTTP/HTTPS
procedure initialize
url := "https://rvb.ru/dostoevski/01text/vol1/01.htm"
if isnull(f := open(url,"m-")) then stop(@errortext, ": ",url)
t := open("c:/tmp/01.htm","w")
while notnull(s := read(f)) do write(t,s)
close(f)
close(t)
end
|
опция "m-" в функции open() задает подключение к защищенному сайту по протоколу HTTPS без проверки сертификатов.
# win2unix.par
# Преобразует символы конца строки из Windows в UNIX формат
[startEntity]
@bof
@eol
@eof
[stopEntity]
[startMarkup]
@run(bof)
@run(eol)
@run(eof)
[Options]
syncMarkup = true
addNewLine = false
[Macros]
procedure initialize
# output directory
outpath := getenv("outpath")
end
procedure bof
out := open(outpath||getname(@input)||"."||getext(@input), "wu")
end
procedure eol
writes(out, @line, "\x0a")
end
procedure eof
close(out)
end
|
Ниже приведена более элегантная версия преобразования формата конца строки.
# Преобразует формат конца строки в UNIX формат
[startEntity]
@eol
[startMarkup]
@eval(write_output(@line,EOL()))
[procedures]
procedure initialize
EOL("unix")
set_option("untranslatedWrite = true")
set_option("compatibility = 4.2")
end
|
В данном примере из данных в формате CSV формируется SQL-скрипт вставки этих данных в таблицу базы данных.
Описание конфигурации (используемый разделитель и имена столбцов) задается во внешнем файле csv2sql.config, загружаемом с помощью директивы @include.
Для контроля символов апострофа (') внтури строки используется функция sql_quotes(s).
Для генерации списка значений-через-разделитель используется функция get_csv(s,delim).
# csv2sql.par
# Преобразование текста в формате СSV (значения через разделитель)
# в набор SQL-предложений insert into ... values().
# Отметьте, что этим скриптом можно обработать сразу нескольких однотипных csv-файлов.
[startEntity]
@bof
@bol
@eof
[stopEntity]
@null
@eol
@null
[startMarkup]
@run(beg_of_file)
@run(row)
@run(end_of_file)
[Options]
syncStop = true
syncMarkup = true
[Macros]
# Инициализируем переменные
procedure initialize
@include csv2sql.config
end
# Перенаправим вывод в файл .sql
procedure beg_of_file
file := getpath(@input)||getname(@input)||".sql"
close_output()
open_output(file)
cols := list()
rows := 0
end
# Сформируем список имен столбцов
procedure get_column_headers
cols := get_csv(s,delim)
i := 0
every 1 to len(cols) do {
i := i + 1
if i=1 then column_headers := cols[i] else column_headers := column_headers || "," || cols[i]
}
end
# Сформируем список значений (все значения как строковые константы)
procedure get_data_values
data := get_csv(s,delim)
i := 0
every 1 to len(data) do {
i := i + 1
val := "'"||sql_quotes(data[i])||"'"
if i=1 then values := val else values := values || "," || val
}
# недостающие значения в строке добавим как null
while i < len(cols) do {
i := i + 1
values := values || ",null"
}
values := values || ");"
end
# Обработка текущей строки текущего csv-файла
procedure row
s := trim(@line,' \t')
if s == "" then return
rows := rows + 1
if rows = 1 then {
if column_headers == "" then {
@call get_column_headers
}
# зададим шаблон предложения "insert"
sql := "insert into " || getname(@input) || "(" || column_headers || ") values ("
return
}
@call get_data_values
write_output(sql, values)
write(sql, values)
if rows % commit_cycle = 1 then write_output("\ncommit;")
end
# Завершение обработки csv-файла
procedure end_of_file
write_output("commit;")
close_output()
end
|
Файл конфигурации для данных мог бы выглядеть как:
# csv2sql.config delim := ',' column_headers := "id,mgr,dept,name,salary" |
Тогда после обработки мы получим следующий SQL-скрипт:
insert into personnel(id, mgr, dept, name, salary) values('7234', '7777', 'Sales', 'Tom Scott', '5700');
insert into personnel(id, mgr, dept, name, salary) values('7777', '', 'Administration', 'Alan Cruzo', '15000');
insert into personnel(id, mgr, dept, name, salary) values('7001', '1234', 'Delivery', 'Jane Fisher', '6100');
insert into personnel(id, mgr, dept, name, salary) values('1234', '7777', 'Delivery', 'John Asher', '15100');
commit;
|
Пусть в исходном тексте перепутаны имена персонажей и требуется взаимообразно заменить одни имена на другие. Обычным поиском и заменой данную операцию выполнить будет не просто, так как потребуется множество промежуточных шагов. С помощью же xMarkup это можно сделать очень просто и быстро. В следующем тексте (Генезис 11:14)
When Eber had lived 30 years, he became the father of Shelah. And after he became the father of Shelah, Eber lived 403 years and had other daughters and sons. |
# exchange.par # Взаимозамена имен в тексте [startEntity] Eber Shelah daughter son [startMarkup] Shelah Eber son daughter [Options] syncMarkup = true |
Все, что нам потребовалось сделать - это задать два синхронизированных списка исходных значений и требуемых замен.
Простой пример, как сгенерить скрипт, который должен последовательно обработать список исходных файлов с помощью некоторой команды.
Обратите внимание на вызов функции eof() в составе параметров write(). Функция eof() ничего не возвращает, но осуществляет быстрый переход в конец исходного файла. Для больших файлов это может значительно ускорить процесс.
Примечание: выберите режим обработки без сохранения результатов и вывод без статистики (опции -oNUL: -q консольной утилиты).
# generate-script.par
# Генерация скрипта
[startEntity]
@bof
[startMarkup]
@eval( write("some-command ",@input, eof()) )
|
Сгенерированный текст скрипта достаточно скопировать с консольного окна и сохранить в BAT-файл.
# Преобразование UTF-8 в UTF-8 without BOM (byte-order-mark). # Текст в UTF-8 without BOM неотличим от текста в ANSI-кодировке, # если только он не содержит символы расширенного алфавита. # Текст в UTF-8 имеет в начале последовательность из 3-х символов (BOM) # \xEF \xBB \xBF, используемую чтобы отличить UTF-16 big endian # от UTF-16 little endian. # Все преобразование заключается в обрезке первых 3-х байтов текста. [startEntity] @bof [startMarkup] @eval(tabto(4)) |
Пример, иллюстрирующий использование декодирующей таблицы. Правила транслитерации взяты с сайта www.translit.ru
# Translit-преобразование кириллических имен файлов
[startEntity]
@bof
[startMarkup]
@run(translit)
[Macros]
# определим правила транслитерации
procedure initialize
cyr := table()
cyr["А"] := "A"
cyr["Б"] := "B"
cyr["В"] := "V"
cyr["Г"] := "G"
cyr["Д"] := "D"
cyr["Е"] := "E"
cyr["Ё"] := "Jo"
cyr["Ж"] := "Zh"
cyr["З"] := "Z"
cyr["И"] := "I"
cyr["Й"] := "J"
cyr["К"] := "K"
cyr["Л"] := "L"
cyr["М"] := "M"
cyr["Н"] := "N"
cyr["О"] := "O"
cyr["П"] := "P"
cyr["Р"] := "R"
cyr["С"] := "S"
cyr["Т"] := "T"
cyr["У"] := "U"
cyr["Ф"] := "F"
cyr["Х"] := "H"
cyr["Ц"] := "C"
cyr["Ч"] := "Ch"
cyr["Ш"] := "Sh"
cyr["Щ"] := "W"
cyr["Ъ"] := "##"
cyr["Ы"] := "Y"
cyr["Ь"] := "'"
cyr["Э"] := "Je"
cyr["Ю"] := "Ju"
cyr["Я"] := "Ja"
cyr["а"] := "a"
cyr["б"] := "b"
cyr["в"] := "v"
cyr["г"] := "g"
cyr["д"] := "d"
cyr["е"] := "e"
cyr["ё"] := "jo"
cyr["ж"] := "zh"
cyr["з"] := "z"
cyr["и"] := "i"
cyr["й"] := "j"
cyr["к"] := "k"
cyr["л"] := "l"
cyr["м"] := "m"
cyr["н"] := "n"
cyr["о"] := "o"
cyr["п"] := "p"
cyr["р"] := "r"
cyr["с"] := "s"
cyr["т"] := "t"
cyr["у"] := "u"
cyr["ф"] := "f"
cyr["х"] := "h"
cyr["ц"] := "c"
cyr["ч"] := "ch"
cyr["ш"] := "sh"
cyr["щ"] := "w"
cyr["ъ"] := "#"
cyr["ы"] := "y"
cyr["ь"] := "`"
cyr["э"] := "je"
cyr["ю"] := "ju"
cyr["я"] := "ja"
end
# переименование файла
procedure translit
srcfile := @file
path := getpath(srcfile)
src := substr(srcfile,length(path)+1)
i := 0
trg := ""
# в цикле преобразуем символы имени файла
while (i := i + 1) <= length(src) do {
c := src[i]
if isnull(cyr[c]) then trg := trg||c else trg := trg||cyr[c]
}
# закроем входной файл, чтобы можно было переименовать его
close_input()
# теперь переименуем файл, если его имя изменилось
if src !== trg then {
write("rename ",srcfile," ==> ",path||trg,)
rename(srcfile, path||trg)
}
end
|
В данном примере показана обработка данных с помощью языка запросов SQL. Предположим, что мы настроили подключение к базе данных с помощью ODBC-источника с именем mysql. Имя пользователя: scott, пароль: tiger.
# Пример загрузки в БД текстового файла
# SL, 12.12.2014
[Macros]
procedure initialize
dbsrc := "mysql"
user := "scott"
pass := "tiger"
# подключимся к базе данных
if notnull(db := open(dbsrc, "o", user, pass)) then write("Подключились к БД: ",dbsrc) else stop("Ошибка подключения к БД: ",dbsrc)
# создадим таблицу в базе данных
sql(db, "create table example(id int not null, s varchar(80))")
i := 0
# загрузим текстовый файл example.txt в таблицу базы данных
T := get_content("exchange.txt")
while length(T)>0 do {
s := get(T)
i := i + 1
s := substr(s,1,80)
sql(db, "insert into example(id,s) values("||i||",'"||s||"')")
}
# рапортуем о количестве загруженных строк
sql(db,"select count(*) as cnt from example")
if notnull(row := fetch(db)) then write("загружено строк: ",row["cnt"])
# закроем подключение к базе данных и закончим
close(db)
exit(0)
end
|
# Гистограмма нормального распределения.
# Для генерации пседослучайных значений используется функция Gauss()
[Options]
graphics = true
[Macros]
procedure initialize
SIZE := 10000
# кол-во разрядов гистограммы
N := 20
# мат.среднее
M := 0.0
# стандартное отклонение
F := 1.0
# 97% интервал M-3*F .. M+3*F
d := 6*F/N
H := table(0)
i := 0
x0 := M-3*F
while (i:=i+1)<=SIZE do {
k := integer((Gauss(M,F)-x0)/d)
if k < 1 then k := 1
if k > N then k := N
H[k] := H[k] + 1
}
Hist(H,"Гистограмма нормального распределения")
end
|
Результирующая гистограмма будет выглядеть следующим образом:
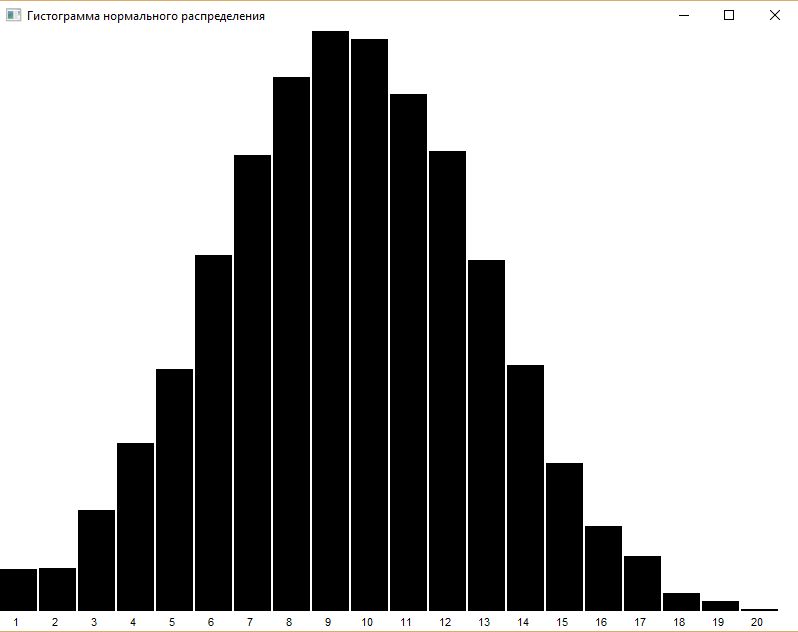
В данном примере показано, как построить и визуализовать гистограмму распределения наимболее употребимых слов в тексте. Обработка текста осуществляется с помощью модуля wordtabulator. При визуализации используются нестандартные опции: горизонтальная ориентация (layout=landscape), голубой цвет (color=blue) и размер окна (size=800,600). Смотри комментарии в п.8.1 относительно чтения файлов про протоколу HTTPS.
# Гистограмма распределения слов в тексте
[Options]
encoding = ANSI
graphics = true
[procedures]
procedure initialize
opts := []
put(opts,"top=20")
put(opts,"min-word-length=4")
put(opts,"sort-order=2")
put(opts,"sort-direction=1")
put(opts,"tags-process=p")
url := "https://rvb.ru/dostoevski/01text/vol1/01.htm"
# откроем или загрузим анализируемый текст
if isnull(f := open(url,"m-")) then {
cmd := "curl --output ./01.htm "||url
if (rc := system(cmd)) != 0 then stop("can't execute: ",cmd)
url := "./01.htm"
}
words := wt(url,[],opts)
Hist(words, "Ф.М.Достоевский. Бедные люди. 20 наиболее употребимых слов.", "layout=landscape color=blue size=800,600")
end
|
Результирующая гистограмма должна выглядеть следующим образом:
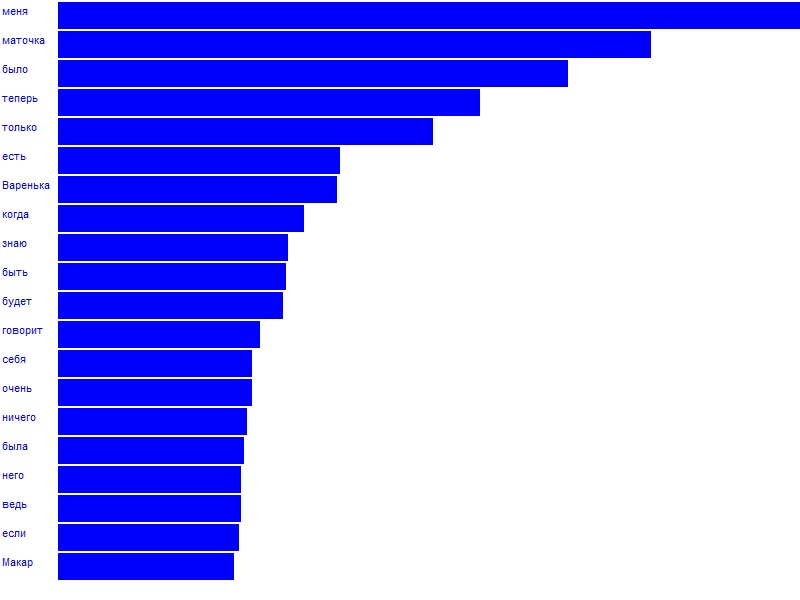
Стоит привести список доступных опций визуализации, задаваемых третьим параметром процедуры Hist (в скобках значения по умолчанию):
ширина,высота - размер окна в пикселях (800,600);схема - ориентация гистограммы (portrait);цвет - цвет гистограммы (black);i - ширина промежутка между столбцами (2);i - отступ от левого/верхнего края (0);Полученную картинку всегда можно сохранить в файл в формате jpeg. Для этого нужно кликнуть по окну гистограммы или нажать "s", когда курсор примет форму крестика. Нажатие Escape или "q" приводит к закрытию графического окна.
В данном примере показано, как визуализовать наимболее употребимые слова в тексте (личные имена). Обработка текста осуществляется с помощью модуля wordtabulator.
# Наиболее употребимые имена собственные: Ф.М.Достоевский. "Бедные люди"
[options]
graphics=true
compatibility=4.5
[procedures]
procedure initialize
opts := []
put(opts,"top=30")
put(opts,"min-word-length=3")
put(opts,"min-word-frequency=10")
put(opts,"sort-order=2")
put(opts,"sort-direction=1")
put(opts,"regular-expressions")
put(opts,"search-queries=^[А-Я]\\w+")
url := "https://rvb.ru/dostoevski/01text/vol1/01.htm"
if isnull(f := open(url,"m-")) then {
cmd := "curl --output ./temp.html "||url
if (rc := system(cmd)) != 0 then stop("can't execute: ",cmd)
url := "./temp.html"
}
words := wt(url,"ignore.txt",opts)
n := length(words)
i := 0
while (i:=i+1) <= n do { w := words[i]; write(w[1]," ",w[2]) }
PlotWords(words, "Ф.М.Достоевский. Бедные люди.", "theme=text radius=100 delta=200")
end
|
Результирующая диаграмма должна выглядеть следующим образом:

Ниже приведен полный список опций процедуры PlotWords (в скобках указаны значения по умолчанию):
тема - тип визуализации значений: text - в виде надписей, circle - в виде шаров;i - приращение радиуса при раскручивании спирали (10);i - шаг (градиент) приращения радиуса спирали (100);список - список используемых цветов через запятую;ширина,высота - размер окна в пикселях (800,600);Полученную картинку всегда можно сохранить в файл в формате jpeg. Для этого нужно кликнуть по графическому окну или нажать "s", когда курсор примет форму крестика. Нажатие Escape или "q" приводит к закрытию графического окна.
В данном примере показано, как визуализовать распределение статистики загрузки с сайта sourceforge.net по странам. Для загрузки статистики используется утилита curl передачи данных. Предполагается, что путь к curl.exe должен быть указан в системной переменной PATH.
# xm_stats.par
# Визуализация статистики загрузок xmarkup на sourceforge.net по странам
[options]
graphics=true
[procedures]
procedure initialize
date := replace(@date,"/","-")
url := "https://sourceforge.net/projects/xmarkup/files/stats/json?start_date=2000-01-01&end_date="||date
url := @q||url||@q
write("curl "||url)
i := system("curl "||url||" --output xm.json")
if i=-1 then stop("вероятно, путь к curl.exe не указан в системной переменной PATH")
s := get(get_content("xm.json"))
if (i := find("\"countries\":",s))>0 then s := ltrim(substr(s,i+12)) else stop("unknown json format")
if (i := find("]]",s))>0 then s := substr(s,1,i-1) else stop("unknown json format")
d := get_csv(s,"],")
data := []
while length(d)>0 do {
s := replace(ltrim(get(d),"["),@q,"")
L := get_csv(s,",")
write(L[1],"\t",L[2])
put(data,L)
}
# числовые параметры (20 и 200) задают шаг и приращение радиуса;
# последний параметр ("circle") задает визуализацию слов в виде "дисков"
PlotWords(data,"xMarkup downloads from sourceforge.net by countries "||date,"radius=20 delta=200 theme=circle")
end
|
Результирующая диаграмма будет выглядеть нечто вроде:

В данном примере показана загрузка статистики популярности раличных языков программирвоания с сайта rosettacode.org и ее последующая визуализация.
# rosetta.par
# На первом шаге данные выгружаются с сайта с помощью MediaWiki API
# и сохраняются в локальный файл rosetta-data.xml
[options]
graphics=true
[procedures]
procedure readurl
write(url)
if isnull(page := open(url,"m")) then stop("Unable to open: ",url)
text := ""
if page["Status-Code"] >= 300 then stop(page["Status-Code"]," ",page["Reason-Phrase"])
while notnull(s := reads(page,-1)) do text := text || s
close(page)
writes(f,text)
end
procedure initialize
baseurl := "http://rosettacode.org/mw/api.php?format=xml&action=query&generator=categorymembers&gcmtitle=Category:Programming%20Languages&gcmlimit=500&prop=categoryinfo"
f := open("rosetta-data.xml","w")
continue := ""
text := "gcmcontinue="
while (i := find("gcmcontinue=",text))>0 do {
text := substr(text,i+1)
if (i := find(@q,text))>0 then text := substr(text,i+1)
if (i := find(@q,text))>0 then {
continue := "&gcmcontinue="||substr(text,1,i-1)
text := substr(text,i+1)
}
url := baseurl||continue
@call readurl
}
close(f)
load_script("rosetta-viz.par")
execute_processing(["rosetta-data.xml"])
end
|
# rosetta-viz.par
# На втором шаге по данным из файла rosetta-data.xml строится диаграмма популярности.
[startentity]
<page@sp
[stopentity]
</page>
[startmarkup]
@run(page)
[procedures]
procedure initialize
data := table(0)
end
procedure page
s := @body
lang := ""
rank := 0
while (i := find("<page ",s))>0 do s := substr(s,i+1)
if (i := find("Category:",s))>0 then {
s := substr(s,i+9)
if (i:= find(@q,s))>0 then lang := substr(s,1,i-1)
if (i := find("pages=",s))>0 then {
s := substr(s,i+7)
if (i:= find(@q,s))>0 then rank := integer(substr(s,1,i-1))
}
if lang !== "" then if rank >0 then data[lang] := rank
}
end
procedure finalize
data := reverse(sort(data,2))
rank := 0
write()
write("rank\tLanguage\tentries")
write("====\t========\t=======")
while (rank:=rank+1) <= length(data) do {d := data[rank]; write(rank, "\t", d[1],"\t",d[2])}
PlotWords(data,"Rosetta Code/Rank languages by popularity "||@date)
end
|
Результирующая диаграмма будет выглядеть примерно таким вот образом (Unicon на 45 месте, а Icon на 53):

Ниже приведен скрипт, реализующмй элементы GUI с помощью средств Unicon. Эта простенькая программа для просмотра файлов изображений в текущей и всех вложенных папках. Навигация вперед-назад по изображениям осуществляется с помощью клавиш со стрелками. Выход - по нажатию "q" или Esc.
Основы графического программирования на Icon/Unicon хорошо изложены в классике Graphics Programming in Icon.
# Простенький скрипт, демонстрирующий графические возможности Unicon.
# Замечание: некоторые изображения могут отображаться некорректно!
# (C) SL, 2022-04-05
[options]
graphics = true
compatibility = 4.6
procedure initialize
w := WOpen("label=Browse images", "font=Times New Roman,14", "size=400,300")
s := TextDialog("Select folder", [], [], [], ["Go!"])
if isnull(s) then exit(0)
if isnull(file := WinOpenDialog("Select first image", "", 30, "Все|*.png;*.jpg;*.bmp;*.gif|")) then exit(0)
d := getpath(file)
L := listfiles(d||"*.(png|jpg|bmp|gif)",1)
i := 0
j := 1
while (i:=i+1)<=length(L) do if file == L[i] then {j := i; i := length(L)+1}
WAttrib("size=1920,1080")
while 1 do {
file := L[j]
EraseArea()
ReadImage(file)
WAttrib("label="||file)
i := j
e := Event()
if e in ["q","\e"] then exit()
if integer(e) in [39,40] then j := j + 1
if integer(e) in [37,38] then j := j - 1
if i = j then Alert()
if j > length(L) then {j := j-1; Alert()} else if j < 1 then {j := 1; Alert()}
}
end
|
Пример экрана просмотра изображения:

В данном примере рассмотрен пример частотного анализа значений в поле таблицы БД. Для этого используем гипотетический телефонный справочник с фамилиями абонентов. Отберем из него 30 наиболее употребимых фамилий и визиализуем полученные результаты.
# db-analyze.par
# Анализ значений в базе данных и визуализация результатов
# SL, 2020-10-20
[options]
graphics = true
compatibility = 4.6
[procedures]
procedure initialize
# подключимся к ODBC источнику данных
if isnull(db := open("dbf","o","user","pass")) then stop("Ошибка подключения к источнику!")
write("Читаю данные ...")
L := list()
T := table()
# читаем поле данных lname из таблицы phone
sql(db,"select lname from phone")
# формируем таблицу (значение, частота)
while notnull(row := fetch(db)) do {
s := row[1]
if notnull(n := T[s]) then T[s] := n + 1 else T[s] := 1
}
close(db)
# сортируем таблицу значений по частоте встречаемости
T := sort(T,2)
n := length(T)
i := 0
j := n
# отберем 30 наиболее употребимых значений
while (i < 30) do {
t := T[j]
put(L, t)
i := i + 1
j := j - 1
write(right(i,2," ")," ",t[1]," ",t[2])
}
PlotWords(L,"Визуализация результатов анализа","radius=200 delta=200 theme=text")
end
|
Результаты анализа значений в базе данных:

Обработка данных может быть значительно ускорена, если преобразовать скрипт xMarkup в исполнимый файл. В этом случае может быть гарантирован прирост производительности сразу в 10-20 и более раз. Исполнимый файл может быть создан в графическом интерфейсе или вручную с помощью утилиты xm2exe, которая размещается в папке bin установки xMarkup.
Например, преобразуем скрипт examples/anlayse_tags.par в исполнимый файл.
xm2exe -p..\examples\analyse_tags.par analyse_tags.par.exe -f..\docs\*.htm -p..\examples\analyse_tags.parПримечание. Для правильной работы утилиты xm2exe требуется небольшая настройка:
make.bat в папке xmwin/bin установки xMarkup в переменной IPATH указать полные пути к папкам ipl/gprocs и ipl/procsпапки xmwin/src установки xMarkup.xmwin/bin установки xMarkup.Использование утилиты xm2exe абсолютно идентично как для MS Windows, так и для POSIX\UNIX систем.
Использование утилиты xMarkup возможно на основе языка программирования Icon или Unicon. Последний является объектно-ориентированным расширением языка Icon, с которым он полностью совместим. Однако Unicon имеет множество дополнительных свойств, отсутстствующих в Icon.
Так как Icon (Unicon) является платформенно-независимым языком, то консольную утилиту xMarkup можно использовать на всех платформах, где имеются реализации Icon (Unicon). В настоящее время реализации Icon (Unicon) доступны для следующих UNIX-платформ:
Для создания бинарного файла утилиты xmarkup на требуемой платформе необходимо установить соответствующий компилятор Icon (Unicon), а затем собрать утилиту на основе ее исходного кода. Исходный код утилиты xmarkup находится в открытом доступе в git-репозитарии sourceforge.net.
Дистрибутивы Icon для различных платформ и исходный код доступны для скачивания на странице Icon-проекта https://www2.cs.arizona.edu/icon/.
gunzip <linux-x86-vXXX.tgz | tar xf –Это может потребоваться, если по каким-либо причинам готовый бинарный дистрибутив вам не подходит.
gunzip <icon-vXXXsrc.tgz | tar xf –make Configure, чтобы вывести список доступных конфигураций.make Configure name=xxx, где xxx - имя выбранной конфигурации.make, чтобы произвести сборку.Исходный код утилиты xMarkup находится в свободном доступе в git-репозитарии sourceforge.net.
icont и iconx в директорию xmarkup/binenv.icn# проверьте, чтобы в файле присутствовали строки$define UNIX 1$define ICON 1# и не было строки$define UNICON 1
make задайте mode=ICONsh make, чтобы произвести сборку утилиты.xm в директории xmarkup/binИсходный код Unicon находится в свободном доступе в git-репозитарии sourceforge.net.
sh ./configure для конфигурирования процесса сборки.make, чтобы произвести сборку.icont, iconx и unicon в директории unicon/binicont, iconx и unicon в директорию xmarkup/binenv.icn# проверьте, чтобы в файле присутствовали строки$define UNIX 1$define UNICON 1# и не было строки$define ICON 1
make задайте mode=UNICONsh make, чтобы произвести сборку утилиты.xm в директории xmarkup/bin|
|
|